Linux 内存布局
目录
关于内存分配,一般的 C 语言开发者使用的更多的是 glibc 库提供的 malloc 和 calloc 等函数,这些函数执行成功,这会返回一个进程所需要的内存起始地址,当然,他们是针对 CPU 端的虚拟地址。Linux 内核负责与硬件打交道,针对 CPU 端的虚拟地址很多场景下都不满足需要,固这些函数在内核状态下无法运行,所以内核提供了自己的一套专门的内存申请释放函数1。
进程在执行过程中,Linux 内核需要根据需要分配给核外进程一块内存区域,进程就把这一片区域作为工作区按照自己的需要执行工作流。对于核外进程来讲,他所看到的地址是不固定的,每一次申请得到的起始地址也是未知的,因此对于内核来讲,他需要更好的动态管理内存,因为核外进程经常是成千上万的,但是实际的物理内存空间是有限的,所以 Linux 内核需要高效的处理内存分配问题。
物理与虚拟内存
虽然现在多数系统都是 64bit,但是很多理念是从 32bit 延展而来的,有必要好好的对比 32bit 和 64bit 的内存动态管理方式。要区分当前运转的系统是 64bit 操作系统还是 32bit 操作系统有很多方法,其中一种就是是否支持 4GB 以上的虚拟地址空间。我们从图 1 中来稍微观察一下这两个不同 bit 宽度的系统的内存布局情况。
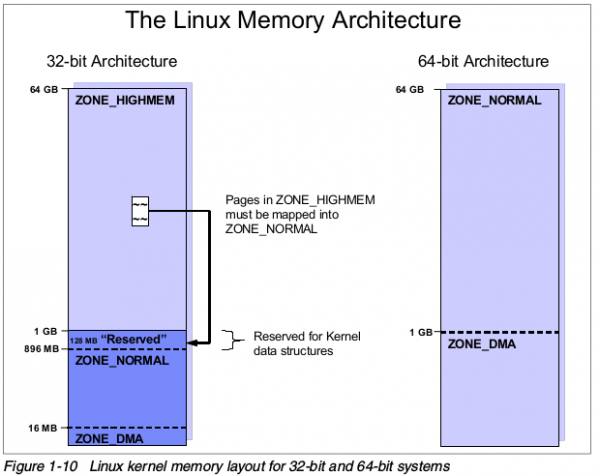
是不是懵逼了,和你听过的或者老师讲过的是不是不太一样?尤其是左边的映射关系,刚刚上面不是讲了 32bit 最多 4GB 吗?这里怎么又到了 64GB 呢?好了,我们先不管左边的图,先看右边的图,在 64bit 地址的操作系统下,由于地址空间巨大(真的很大)所以只分为了 ZONE_DMA 和 ZONE_NORMAL,这个很好理解,一段内核用来做 DMA,一段内存可以做其他的操作。是不是很好理解?
我相信,一定还有人有疑问,总感觉哪里不对,我想告诉你的就是,这个图讲的是物理地址空间分配,物理地址,物理地址!!!重要的事情说三遍。请转变一下思维,这里图中描述的并不是 CPU 看到的地址,而是所有的视角下,实实在在的物理地址,全硬件通用的地址语言。do you understand?好吧,就算没有区分清楚也没关系,我后面会讲到物理地址和虚拟地址的对应关系,现在这里你就看着,然后听我娓娓道来。
右边的地址空间区分得很清楚,你是什么物理地址,处在什么位置就应该干嘛干嘛,左边的地址好像很复杂,是的没错,就是因为他是 32bit,为什么 32bit 就应该受到歧视呢?其实不是大家要歧视 32bit,而是没有办法不得不这么做,也是为了迁就 32bit 的 CPU 访问。不懂吗?没关系,再来,试想一下,一个 32bit 宽度的 CPU 的机器上面,我架设了一条 16GB 的内存2,而我虚拟地址(CPU 地址)限制只能访问到 4GB 我就应该抛弃掉其他的内存吗?不,不抛弃不放弃,于是,我们把 ZONE_DMA 划分为 16M,然后内核最大只能使用 1GB 空间,为了迁就从 1GB 开始到内存结束的位置,我们需要保留 128MB 的地址空间用于将 ZONE_HIGHMEM 映射到 ZONE_NORMAL 上,所以,现在 ZONE_NORMAL 就剩下了最后一个分界线,那就是在 896MB 的位置了。
好吧,或许你懂了,也许没懂,没关系,再上一个图,专门讲解 32bit 的物理地址空间。
32bit 下 x86 的物理地址空间布局与虚拟地址的映射
为什么只讲 32bit 下的关系?因为 64bit 的咋上文已经讲过了,就是这么简单,没有太复杂的东西,而且理解了 32bit 的内存映射与布局关系,要理解 64bit 仅仅只需要去掉对 high_memory 这一段即可。
物理地址空间布局
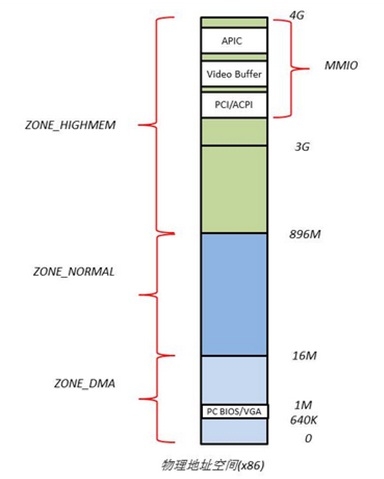
我慢慢再来解释,大家注意看,物理地址空间顶部以下的一段空间是交由给 PCI 设备进行 IO 内存映射占据的,他们的大小和布局由 PCI 规范所决定,640K~1M 这一段空间被 BIOS 和 VGA 适配器占据,这也是 CPU 开机运转的起始地址所在的位置,CPU 会从这一段物理地址开始执行命令。
Linux 内核根据不同的用途将内存分为了三类区域(64bit 只有 2 个区域),如图 2 的 ZONE_DMA、ZONE_NORMAL 和 ZONE_HIGHMEM,他们的划分在上文已将讲过了不再重复。
虚拟地址空间布局
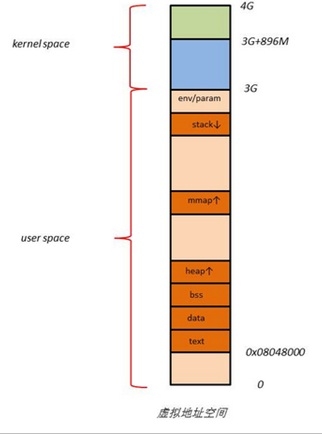
我们再来看看虚拟地址空间的布局,请清晰,这里是虚拟地址空间,不是物理地址的布局,物理地址的布局上面已经讲过了。先看左图,这是用户程序在虚拟地址空间中的一个内存布局方式,我们可以很清晰的看得出来,代码段,数据段,以及 mmap 还有堆栈等所处的位置,但是都不会超过 3GB 的界限,因为这就是他的限制范围,这个范围是内核定义的由 PAGE_OFFSET 标记。
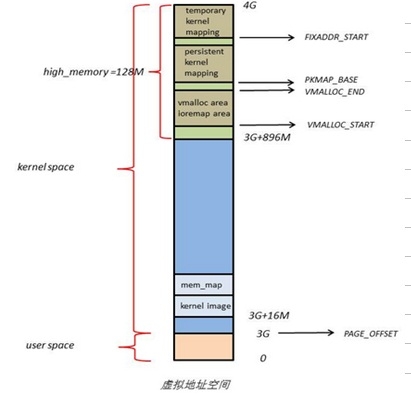
我们再来看右图,这就是 4GB 虚拟地址空间的顶端 1GB 内核所在的虚拟地址空间的布局,是不是与物理地址布局一致呢?3GB+16M 用来做 DMA 等,3G+16M 到 3G + 896M 作为内核通用内存,而最高端的所谓 high_memory 其实对应的就是物理布局中的专门用来映射更高端内存的保留内存,这个区域叫做 vmalloc area,当然,由于保留的内存有限,在使用完毕之后,这一段保留的内存需要断开与高端内存的映射关系,以便其他高端内存可以继续往这个区域映射3。
虚拟地址空间与物理地址空间的映射

Linux 内核将 4GB 的线性虚拟地址划分为了两个部分,0 到 3GB 为用户空间,3GB 到 4GB 为内核空间4,由于开启了分页机制,内核要想访问到实际的物理地址的话,就要将全部的物理地址映射到 1GB 的内核线性空间中,这显然是不可能的,于是内核将 0 到 896MB 一一映射到自己的线性地址空间,这样他就可以随时访问 ZONE_DMA 和 ZONE_NORMAL 的内容,而剩下的 ZONE_HIGHMEM 自然不可能一次性全部映射到剩余的 128MB 空间内,于是 Linux 内核采用了动态映射的方法将所有处在 ZONE_HIGHMEM 中的物理页在被使用到的时候单独映射到这个 vmalloc area 中,使用完毕之后立刻释放映射关系,以供其他页面可以继续映射。当然,虽然存在效率问题,但是总算是可以访问到全部的内存空间了,岂不是美哉?
后记
Linux 内核的内存管理很复杂,不是三两句可以讲得清晰的,这一节主要阐述的是内存的物理布局和虚拟地址布局,下一节会讲述一下如何分配内核。
- 内核为什么不能使用虚拟地址呢?其实不然,内核是可以使用虚拟地址的,但是很多时候内核需要用到一段连续的,小块的物理内存,采用直接物理内存申请的方式可以免去虚拟地址和物理地址之间的转化,可以得到更好的效率;其次,内核的驱动主要是为了服务于硬件,那么物理内存地址才是在各类不同硬件视角(不管是 CPU 还是显卡或者其他硬件的角度)都是通用语言(地址都一样,不会混淆),这才是在内核中主要使用物理地址的原因。 ↩︎
- 图中是 64GB,没关系,我举例 16GB 和 64GB 关系不大,因为内核在 32bit 下面都访问不到,他只能访问 0~1GB 的空间,其他空间都需要映射。32bit 宽度的地址只能最大访问到 232 这样的空间,为何这里最终 32bit 的机器能够访问到超过 4GB 的内存呢?原因就是 Intel 引入了一个 PAE 的硬件扩展,管脚线由 32 扩展到了 36 所以可以最高访问到 64GB 的位置,不过与这里要讲的映射关系不大,仅仅是为了说明为何 32 位操作系统也能访问到 64GB 的原因。 ↩︎
- 这里多了一次映射关系,就是如果在 32bit 操作系统上使用高端内存会导致两次映射,一次是虚拟地址到物理地址的映射,再一次就是高端内存到 vmalloc area 的映射,而 64bit 上只需要直接从虚拟地址映射到物理地址,这样访问起来会更快。 ↩︎
- 最近由于 Intel 爆发了 CPU 级别的 meltdown 漏洞,导致核外程序可以访问到核内内存,所以 Linux 内核修改之后已经不再是按照 PAGE_OFFSET 进行划分而是隔绝的维护两张页表,一个是内核页表,一个是核外页表,所以不再存在所谓 user space 和 kernel space 的虚拟地址划分了,当然,具体的实现原理我还没有深入理解,仅仅探讨了一下 Patch,有时间再来补充这一部分。 ↩︎