NVMe 设计逻辑与原理解析
Contents
需要深入的研究 NVMe 整个协议以及他的驱动实现逻辑,特此做一定的记录于此,一方面方便自己记忆,另一方面可以给后来者一个参考。
NVMe 命令
NVMe 有两种命令,一种叫做 Admin Command, 用来对 Host 进行管理以及控制 SSD;另外就是 I/O Command,用来处理 Host 和 SSD 之间的数据传输,下面表格列举当前的 NVMe 1.2 版本手册协议中定义支持的命令列表。
NVMe 支持的 Admin Command
| 操作码 | 设计可选/必选 | 是否需要携带 NSID | |
|---|---|---|---|
| 00h | 必选 | 不需要 | 删除 I/O 提交队列 |
| 01h | 必选 | 不需要 | 创建 I/O 提交队列 |
| 02h | 必选 | 需要 | 获取 Log 页 |
| 04h | 必选 | 不需要 | 删除 I/O 完成队列 |
| 05h | 必选 | 不需要 | 创建 I/O 完成队列 |
| 06h | 必选 | 需要 | ID |
| 08h | 必选 | 不需要 | Abort |
| 09h | 必选 | 需要 | 设置特征(Feature) |
| 0Ah | 必选 | 需要 | 获取特征(Feature) |
| 0Ch | 必选 | 不需要 | 异步事件请求 |
| 0Dh | 可选 | 需要 | Namespace 管理 |
| 10h | 可选 | 不需要 | 固件提交 |
| 11h | 可选 | 不需要 | 固件镜像下载 |
| 15h | 可选 | 需要 | Namespace 附属 |
| 80h - BFh | 可选 | I/O 命令集 | |
| C0h - FFh | 可选 | 厂商指定 |
NVMe 支持的 I/O Command
| 操作码 | 设计可选/必选 | |
|---|---|---|
| 00h | 必选 | 刷新(Flush) |
| 01h | 必选 | 写 |
| 02h | 必选 | 读 |
| 04h | 可选 | 无法纠正的写 |
| 05h | 可选 | 比较 |
| 08h | 可选 | 写零操作 |
| 09h | 可选 | 数据集管理 |
| 0Dh | 可选 | Reservation Register |
| 0Eh | 可选 | Reservation Report |
| 11h | 可选 | Reservation Acquire |
| 15h | 可选 | Reservation Release |
| 80 - FFh | 可选 | 厂商自定义 |
显而易见的,NVMe 的命令和 ATA 命令比起来那少得多,简直就是为了 SSD 量身定做的协议,既然已经有了命令,那就需要知道是如何在 Host 端将 Command 发送到 SSD 的呢?
NVMe 有三种特殊的部件,Submission Queue(SQ)提交队列,Completion Queue(CQ)完成队列,以及 Doorbell Register(DB)门铃寄存器。如果学习过相关的类似驱动的都能够理解这几个部件是用来做什么的(学习过 Infiniband 的协议的应该很清楚)。SQ 和 CQ 位于 Host 的内存中,DB 位于 SSD 的内部。
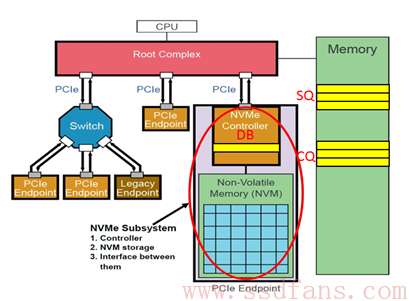
上图除了明确 SQ 和 CQ 位于 Host 内存,DB 位于 SSD 内部之外,还对 PCIe 系统有个大概的认识。SSD 作为一个 PCIe 的 Endpoint 挂载在 Root Complex 上,然后 RC 连接着 CPU 和内存。可以将 RC 比作 CPU 的代言人,作为系统的最高决策者,CPU 一向都很忙,所以有什么问题先和代理人沟通,那么就是和 RC 沟通!尽管不是直接和 CPU 对话,但是,SSD 的地位相对于以前来说是提升了一级,至少不再需要连接到南桥之上(某些机器)。
SQ 位于 Host 的内存中,Host 需要发送命令时,只需要将准备好的命令放入到 SQ 中,然后通知 SSD 来取;CQ 同样位于 Host 内存中,一个命令的执行成功或者失败,SSD 总会往 CQ 中写入这个命令的完成状态。DB 又是如何处理的呢?前文提到,需要通知 SSD 来取,那么怎么通知,当然最好的方式就是写 DB 寄存器告诉 SSD,数据准备完毕,可以来取。
NVMe 的整个流程很简单,加起来就是八个步骤:
第一步:Host 写入命令到 SQ 中;
第二步:Host 写 DB 寄存器通知 SSD 来取命令
第三步:SSD 收到通知,从 SQ 中取命令
第四步:SSD 执行命令
第五步:指令执行完成,SSD 往 CQ 中写入指令完成结果
第六步:SSD 通过中断通知 Host 指令执行完毕
第七步:Host 收到通知,处理 CQ 队列中的命令完成状态
第八步:Host 处理完毕命令状态,通过 DB 回复 SSD 整个指令处理完毕,结束
总结为:SSD 的天龙八步。
NVMe 的三大部件详解
前文已经提到了 SQ,CQ,DB 的作用,其实他们并没有前文说的那么简单(当然从逻辑上的确很简单),其实他的实现上并不是那么简单。Host 往 SQ 中写入命令,SSD 往 CQ 中写入命令完成结果。所以 SQ 和 CQ 就是一对一的关系,也可以是多对一的关系(可以有多个 SQ 队列对应一个完成队列),但是不管如何,他们总是成对出现,有 SQ 必然会有 CQ 队列。
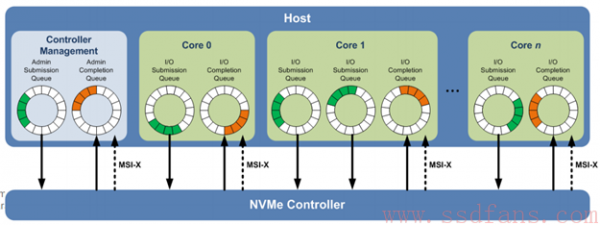
SQ 和 CQ 与 Command 一样是区分 Admin 域和 I/O 域的,这很好理解,放 Admin Command 的就是 Admin SQ 和 Admin CQ,放 I/O Command 的就是 I/O SQ 和 I/O CQ,这也是一种对应关系,NVMe 协议规定不允许将 I/O Command 放到 Admin SQ 中,反之亦然,不然后果不可预期。另外值得关注的是,I/O SQ/CQ 是可以存在多个队列对的,而 Admin SQ/CQ 仅仅只有一对(很好理解,管理层自然很少,干活的员工自然要多)。一般来说,除了 Admin SQ/CQ 为唯一的一对之外,I/O 的 CQ 建议为每一个 Core 提供一个,I/O 的 SQ 为每一个 Core 提供多个。为什么每一个 Core 提供一个 CQ 就行了,而 SQ 却最好多个呢?一个是为了性能,每一个 CPU 都可能存在多个流水线,那么可以满足性能最大化,此外就是为了 QoS,可以为不同的 I/O 命令提供不同的 I/O 优先级,这样可以保证高优先级的 I/O 更快的完成。关于实际系统中该如何设计,NVMe 的手册中有参考意见:

作为一个队列,没有 SQ 和 CQ 都有一定的深度(就是 Size):对于 Admin SQ/CQ 来讲,其深度可以是 2-4096(4k);对于 I/O SQ/CQ,其深度可以为 2-65536(64k)。队列深度是可以配置的。SQ/CQ 的个数可以配置,每个 SQ/CQ 的深度也可以配置,因此 NVMe 的性能是可以通过配置队列个数和队列深度来灵活调整的。相对于 AHCI 只有一个命令队列,且深度固定为 32,还有一个重要的是,与 NVMe 配合的是 PCIe,一个 PCIe 接口一个可以扩展的,从 1-32 Lane,这一点 SATA 是无法实现的。
每一个 SQ 中放入的是 Host 的 Command 条目,无论是 Admin 还是 I/O Command,每一个条目的大小都是 64 字节;每个 CQ 放入的命令完成状态都是 16 个字节。总结一下:
- SQ 用来保存 Host 发送的命令,CQ 是用来给 SSD 回写命令的执行结果
- SQ/CQ 可以保存在 Host 的内存中,也可以在 SSD 内部,但是一般都在 Host 的内存中(我们暂时讲的都是在 Host 的内存中)
- 和 Command 一样,SQ 和 CQ 有两种类型,一种是 Admin SQ/CQ 一种是 I/O SQ/CQ
- 系统中只有一对 Admin SQ/CQ,但是可以存在很多对 I/O SQ/CQ
- I/O 的 SQ/CQ 可以是一对一的关系,也可以是一对多的关系
- I/O 的 SQ 是可以赋予不同等级的优先级
- I/O SQ/CQ 的深度最多可达 64k,Admin SQ/CQ 最深可达 4k
- 每条命令都是固定大小,Command 大小为 64k, Status 回执信息为 16k
有一个很重要的概念就是,这里提到的队列 Queue 并不是软件编程里面的一个链表,他是一段内存,然后通过软件的逻辑将其模拟为一个环,所以他是有一个很重要的概念就是 Head 和 Tail,通过比较这两个指针的位置,就可以知道当前的环形队列的一个状态(是否满以及在哪个位置可以取数据和可以在哪里写数据),从软件设计的角度来讲,Tail 和 Head 好像我们都能拿到,如果仅仅在软件编程逻辑中,整个环都在开发者掌控之中,什么指针,什么位置了如指掌,但是在 NVMe 其实不然,Host 其实很难控制这个环,为什么呢?你看,这个环其实不是 Host 在使用,也就是 Host 并不知道 SSD 命令执行到环的哪个位置了!!!还有,SSD 也不知道你 Host 到底写到了什么位置,这 TMD 就尴尬了,一个用来做为两个部件交流的桥梁,现在出现了一个很严重的问题就是互相不知道对方做到什么位置了,这个问题该如何解决呢?

问题虽然不复杂,但是对于普通的软件开发人员(刚接触 Linux 内核的开发人员应该也一样)来讲可能从未遇到过,毕竟一个内存居然由两个部件一同修改的案例很少碰到,所以刚开始接触的可能会云里雾里,在自己的圈子里绕很久,因为他认为环一切尽在掌握,所以不太懂这个设计是为了什么。对于实现过网络驱动的人员可能就不是什么问题了,因为网卡也需要驱动申请一段内存交给网卡进行填充。好了言归正传,不管有没有理解,问题还是抛出来,就是 Host 和 SSD 需要通过 SQ/CQ 交流,那么就需要知道这个 Queue 的 Head 和 Tail 指针,不好意思,现在 Host 知道自己写到了哪里,也就是知道 Tail 位置,但是 SSD 并不知道,所以 SSD 不知道取命令的时候,该从 Head 取到什么位置,那么既然 Host 你知道 Tail 的位置,就告诉 SSD 吧,这也就是 DB 存在的意义,Host 将 Tail 的位置写到 SQ Tail DB 中,告诉 SSD 当前的命令写到了 xxx 位置,你可以一直取到这个位置。好吧,其实文字这么讲可能不是很清晰,我们来走一遍 Host 与 SSD 是如何通过 DB 交流的。
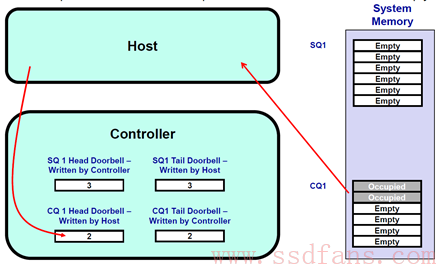
- 开始假设 SQ1 和 CQ1 是空的,Head = Tail = 0;

- 这个时候,Host 往 SQ1 中写入三个 Command,SQ1 的 Tail 值则变为了 3,Host 往 SQ1 中写入 Command 之后,更新 SSD 控制器的 SQ1 Tail DB 寄存器,值为 3。Host 在更新这个值的时候,也等于告诉 SSD 现在有新的 Command 到达,请开始执行;
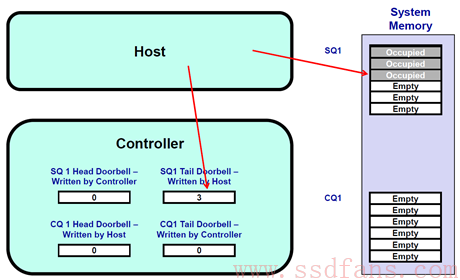
- SSD 控制器收到该通知之后,从 SQ1 取出 3 个 Command,并且把他们都消费掉,然后更新 SQ1 的 Head DB 为 3;

- SSD 执行完毕两个命令之后,会往 CQ1 中写入命令完成信息,同时更新 CQ1 的 Tail DB,值为 2。SSD 发送中断给 Host,通知有命令处理完毕,注意查收;
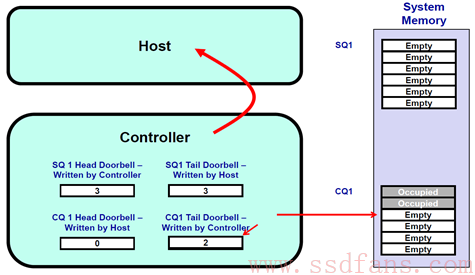
- Host 收到中断之后,从 CQ1 中取出这两条完成状态信息,等待处理完毕之后,Host 更新 CQ1 的 Head DB寄存器,值为 2;
上面的 5 个步骤是整个 DB 与 Queue 联合运作的结果,也充分展现了当前的环与 DB 是如何工作的,基本上理解上面的步骤就可以理解当前的 NVMe SSD 是如何和主机进行的数据交互。DB 在命令处理流程中起了什么作用呢?
首先,如前所示,他的主要作用是为了记录当前的 SQ/CQ 的 Tail 和 Head 指针,用来协调 SSD 和 Host 双方,并互相通知当前所处的位置。对于 SQ 而言,SSD 是消费者,他直接与队列的 Head 打交道,很清楚 Head 位于什么位置,所以 SQ 的 Head 由 SSD 自己维护;但是他并不知道当前的队列被插入了多少数据,也就是不知道 Tail 在什么位置,后面还有多少命令等待执行;对应的 Host 作为生产者,他往 SQ 中插入数据,自然很清楚 Tail 位于什么位置,那么就需要他来更新 SQ 的 Tail DB 寄存器来告诉 SSD 当前的尾部在什么位置,SSD 通过自己维护的 Head 和 Host 写入的 Tail 计算得出当前可以获取的 Command 总数量是多少,把他们都取出来执行即可。对于 CQ 来言,SSD 是生产者,他很清楚 CQ 的 Tail 在什么位置,所以他来更新 CQ 的尾部,但是 SSD 并不知道 Host 处理完成状态到了什么位置,需要 Host 来告知,所以 Host 更新 CQ 的 Head DB。SSD 根据 CQ 的Head 和 Tail 就知道 CQ 还能不能继续插入完成命令的状态信息。
DB 的另外一个作用就是通知,Host 更新 SQ Tail DB 就是通知 SSD 当前命令有更新,请执行;Host 更新 CQ 的 Head DB 就是告诉 SSD 当前的完成状态处理完毕,表达谢意。有个值得注意的问题就是,Host 对于 DB 只能写不能读,而且还局限于 SQ Tail DB 和 CQ Head DB。这是为了什么呢?目前我还没有答案,等下次询问 SSD 设计厂商或者查阅设计规范的时候再更新文档。
既然 Host 不能读 DB,那么他是如何实现管理整个 Queue 的呢?这个很关键,因为 Host 只知道 SQ 的 Tail 并不知道 Head 处于什么位置,他是无法对 SQ 进行管理的;另一方面,Host 也仅仅知道 CQ 的 Head 而不知道 CQ 的 Tail,也是无法完成对 CQ 的管理。
如果是我来设计,也许会直接让 Host 能够读取当前的 Head DB,那么直接就能获取到当前的 Head 处于什么位置,但是,我自己估计不这么设计的一个主要原因就是无法保证同步,因为 Host 读的时候,有可能是一个滞后的值,SSD 可能在某个时间点更新了,导致这个地方发生了竞态条件。当然,这个猜想目前仅仅是猜想,没有经过任何的考证。既然目前无法从 SQ 的 Head DB 直接读取,Host 总要想个办法来获取 Head 位置。其实设计规范也是有说明的,在 CQ 完成队列的条目中,有一个专门的字段通知 Host 当前的 SQ Head Pointer 处于什么位置(见图),这样,当前的 Host 就可以知道 Head 位置并且放心大胆的管理 SQ 了。

既然 Host 可以拿到 SQ 的 Head 和 Tail 指针,那么 CQ 的 Tail 又如何拿到呢?其实还是通过 CQ 完成条目中的字段获得的,我们继续关注图 10 中的 DW3 字段有个一个 P 的位,他就是用来标记当前的条目是不是 CQ 填写的完成条目。
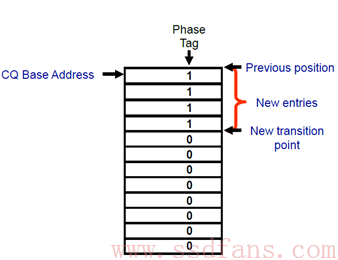
具体是如何实现的呢?一开始 CQ 中的每一个完成命令条目的 P bit 位都为 0,SSD 往 CQ 中写入完成命令条目时,会把 P 更新为 1。由于 CQ 队列其实是位于 Host 主机内存中的,Host 可以检查所有的 CQ 完成队列,当然也包括 P 的值,Host 记住上次的 Tail 之后,然后一个个往下检查下一个 P 位,直到 P == 0 的位置就说明到达了 Tail 位置,就是这样,是不是很简单?(虽然不能直接读 CQ Tail DB,但是这也是没有办法的办法)
稍作总结:
- DB 在 SSD 控制器上,是一个寄存器
- DB 记录着 SQ 和 CQ 的 Head 和 Tail
- 每一个 SQ 或者 CQ 有两个 DB:Head DB 和 Tail DB
- Host 只能写 SQ Tail DB 和 CQ 的 Head DB,不能读 DB
- Host 通过 SSD 的 CQ 中的完成条目获取当前的 SQ Head DB 位置和 CQ 的 Tail DB 位置
- 还有一个比较重要的就是,SSD 最终能够创建多少个 Queue 取决于当前的 SSD 卡存在多少对这样的 DB,所以也不是软件想申请多少就可以得到多少个 Queue
目前留下几个疑问:
- 为什么当前 SSD 的 DB 被设计为只可写而不可读?这点在网卡驱动中也是同样的,也许是需要遵循某种硬件设计限制,也许是需要规避同步问题,这一点还需要确认
- 为什么还需要设计一个 SQ 的 Head 和 CQ 的 Tail 呢?按照我的理解,SQ 的 Head 和 CQ 的 Tail 并没有 Host 的参与,一切仅仅存在于一个 SSD 的写逻辑中,那么既然如此,为何不设计成一个逻辑概念即可,反正 Host 也不可读,一切对于 Host 仅仅只是一个概念,硬件上少一组寄存器,成本就下降很多了。也许在硬件上真的没有这一组硬件部件,也真的就是一个逻辑概念,除了同步问题之外,也是为了节省成本,所以这也有可能解释了上面的一个问题,为什么是不可读的。
补充:今天在 SSDFANS 的群里面与各位牛人交流的时候,目前得到一个得到大家认可的猜想,关于为何不直接读 SQ Head DB 的主要原因是 Host 无论如何都是需要读取 CQ 的,如果 SSD 将 Head DB 位置写到这里,以及 P 位置写到 CQ 中,可以减少两次对于寄存器的读写操作,对于频繁的寄存器读操作是很耗时的,这么做可以提升 NVMe 系统的性能。以此为扩展,我估计网卡也不直接读取 Head 位置而直接计算 DD 位的原因可能也是为了提升性能,而不是没有办法这么做。另外还有一个原因可能是消息通知方式有中断和轮询,如果采用读寄存器的方式来获取 Head,那么在轮询的方式中就会不断的查寄存器,这个不是什么有效的方式。【2017-12-07】
NVMe 数据的来龙去脉
之前已经理解了 NVMe 的逻辑过程、消息通知与同步过程,现在需要了解数据是如何在 Host 和 SSD 进行传递的,这也是 SSD 的一个重中之重,如果失去了数据传递,那么 SSD 就啥也不是了。

Host 如果想往 SSD 中写入数据,需要告诉 SSD 写入的是什么数据,写多少数据,以及数据的源在内存什么位置,这些信息都包含在了 Host 发送给 SSD 的 Write 命令中。每一个需要写入 SSD 的数据都对应一个 LBA(逻辑块地址)的东西,Write 命令通过指定 LBA 来告诉 SSD 写入什么数据;对于 NVMe 来言,收到该命令之后,PCIe 去 Host 的内存中读取这些数据,然后将这些数据写入到 SSD 中,同时得到 LBA 和 SSD 闪存的对应关系。同样的,如果想读取 SSD 中的数据,一样的需要告诉 SSD 你所需要的数据位置,以及长度还有你需要保存到内存的什么位置,这些信息保存在 Host 向 SSD 发送的 Read 命令中。SSD 根据 LBA,查找映射表找到对应的物理闪存所在的位置,然后读取这些数据,然后通过 PCIe 写到指定的内存位置上去,这就完成了 Host 对 SSD 的读访问。
有个点需要注意的就是,Host 在与 SSD 的数据传输的过程中,Host 是被动的一方,SSD 是主动的一方,Host 需要数据,那么 SSD 主动将数据写入到 Host 的内存中;Host 写数据,那么同样是 SSD 去 Host 的内存取数据,然后写入闪存。所以看起来 SSD 就像一个勤劳的快递员,不但负责送货上门,而且还上门取件。当然,无论是上门取件还是送货上门,你都需要告诉快递员你的地址,不然他给如何找得到你呢?Host 有两种方式告诉 SSD 数据所在的内存的位置,一种是 PRP(Physical Region Page),另外一种是 SGL(Scatter/Gather List)。
先说 PRP,NVMe 将 Host 的内存分为一个个的页,页的大小可以配置,从 4KB 到 128MB,都是 2 的幂次方。PRP 是个什么玩意儿呢?

PRP Entry 本质上是一个 64 位的物理地址,只不过这个物理地址被分为了两个部分:页起始地址和页内偏移。最后两个位为 0,表示这个物理地址只能是四个字节对齐访问,页内偏移可以为 0,也可以是一个非零的值。

PRP Entry 描述的是一段连续的物理内存连续地址,如果需要描述若干个不连续的物理内存,那么就需要若干个 PRP Entry,把这些若干个不连续的 PRP 链接起来就是 PRP List。

上面的图表中的 PRP Entry 的 Offset 都是 0h,这说明每一个 PRP Entry 的偏移量都必须为 0,这是由于 PRP List 中的每一个 PRP Entry 都是描述的一个物理页,不允许他们存在交叉的物理页,不然 SSD 会往同一个物理页写入几次数据,导致先写入的数据被覆盖。我们仔细查看 NVMe 的数据手册可以发现,每一个 NVMe 命令都有两个域:PRP1 和 PRP2,Host 就是通过这两个域告诉 SSD 数据位于什么位置,或者读取数据保存的位置地址。

PRP1 和 PRP2 有可能指向数据所在的位置,也可能指向 PRP List,类似于 C 语言的指针概念,PRP1 可以是指针,也可以是指针的指针,或者层次更深,不管包了多少层,SSD 总是能够一层层的刨开并找到数据的真实地址。下面是一个 PRP1 指向 PRP List 的例子:

PRP1 指向了一个 PRP List,PRP List 位于 Page 200,页内偏移为 50 的位置,SSD 确定 PRP1 是个指向 PRP List 的指针之后,就会去 Host 内存中的(Page 200,Offset 50)位置获取到 PRP List,获得 PRP List 之后,就按照规范获取到数据的真实地址,SSD 就会往这些真实的物理地址读入或者写入数据。对于 Admin Command 来演,他只用 PRP 来告诉 SSD 当前命令的真实地址的位置;对于 I/O 而言,除了 PRP 之外,还有 SGL 的方式告诉 SSD 数据位于内存的什么位置。Host 会在传递的命令中告诉 SSD 他将采用什么方式传递数据,具体来说就是当命令中的 DW0[15:14] 是 0,就是 PRP 方式,否则就是 SGL 模式。

SGL 是什么?SGL 是一个数据结构,用来描述一段数据空间,这个空间可以是数据源所在的空间,也可以是数据的目的地址空间。SGL(散列表)首先它是一个 List,由一个或者多个 SGL Segment 组成,而每一个 SGL Segment 又由一个或者多个 SGL Descriptor 组成,所以 SGL Descriptor 是 SGL 的最小组成单元,他描述了一段连续的物理内存空间:起始地址+空间大小。每一个 SGL Descriptor 大小是 16 个字节,一块内存空间可以用来保存用户数据,也可以来存放 SGL Segment,根据这段空间的不同用途,SGL Descriptor 也分为几种类型。

有 4 种 SGL Descriptor,一种是 DataBlock,很简单,就是描述的这段空间是用户数据空间;一种是 Segment 描述符,SGL 不是由 SGL Segment 组成的吗,既然是链表,就需要前面的 Segment 有个指针指向下一个 Segment,这个指针就是 SGL Segment 描述符,他描述的是下一个 SGL Segment 在什么位置;还有一种特别的,SGL Segment 描述符,他就是链表中的倒数第二个 Segment 的 SGL Segment 描述符,这个描述符被称作 SGL Last Segment 描述符,也是一个单独的类型,为什么需要单独的定义为一种类型呢?简单理解就是当 SSD 解析到该位置时,就知道下一个 SGL Segment 是最后一个项了。那么 SGL Bit Bucket 是个什么鬼?这玩意儿只对 Host 读有用,他是告诉 SSD,你往这个内存写入的数据我是不要的,那么 SSD 观察到该标志之后,认为上层既然不要,那么我就不传。说了这么多,看起来很绕,还是结合图来说明会比较容易理解。

还是有点晕,那么继续看例子。这个例子中,假设 Host 需要往 SSD 中读取 13KB 的数据,其中真正需要的只有 11KB 数据,这 11 KB 的数据需要放到 3 个不同的内存中,分别是:3KB,4KB 和 4KB。

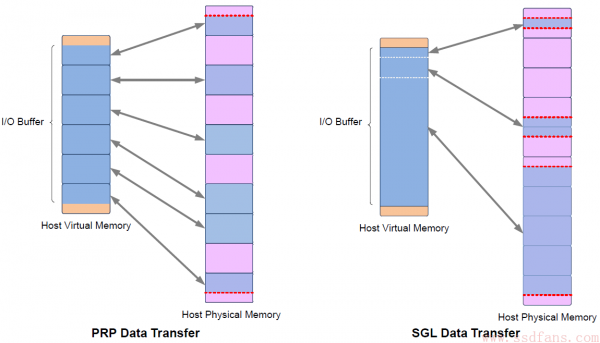
无论是 PRP 还是 SGL,本质都是描述内存中的一段数据空间,这段数据空间在物理上可能是连续的,也有可能不是连续的。Host 在命令中设置好 PRP 或者 SGL,告诉 SSD 数据源在什么位置,或者从闪存中读取数据保存到内存的什么位置上。也许很多人会有这样的疑问,为什么有了 PRP 之后还需要 SGL 呢?事实上,NVMe 1.0 的时候的确只有 PRP,SGL 是 NVMe 1.1 版本之后加入的。SGL 和 PRP 的本质区别在哪里呢?下图道出了真相:一段数据空间,对 PRP 来说,他只能映射到一个个的物理页,而对 SGL 而言,他可以映射到任意大小的连续物理空间。
NVMe 的数据保护功能
NVMe 的基本数据传输一定有了一定的了解,接下来需要理解的就是 NVMe 的端到端的数据保护功能。Host 与 SSD 之间,数据传输的最小单位是逻辑块(LB),每一个逻辑块的大小可以是 512/520/1024/2048/4096 等,Host 在格式化 SSD 的时候,逻辑块的大小就已经决定了,以后两者根据这个逻辑块的大小进行数据交互。数据从 Host 到 NVM 首先经过的是 PCIe,然后控制器将数据写入到闪存中;反过来,Host 想从闪存中读取数据,首先需要 SSD 控制器将闪存中获得数据,然后经过 PCIe 将数据传送给 Host。
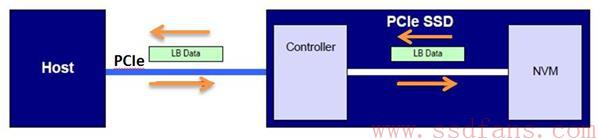
不过,Host 和 SSD 之间的数据在 PCIe 传输时存在信道干扰,可能导致数据出错;另外在 SSD 内部,控制器与闪存之间,数据也有可能发生错误。整条道路是困难重重,凶险万分,为了确保 Host 和 SSD 之间数据的完整性,那么需要提供一种端到端的数据保护功能。因此,在逻辑块数据本身,NVMe 还允许携带每一个元数据块,数据保护能力就在这个元数据块中体现出来。元数据有两种存在方式,一种是作为逻辑块数据的扩展和逻辑块一同存放;另外一种就是逻辑块数据放在一起,元数据单独存放在别处。


其实是否放到一块,我们并不需要关心形式,重要的是了解这个保护机制的原理是什么!NVMe 要求每个逻辑块数据的保镖配备下面这把武器:

其中 Guard 是 16bit 的 CRC,他是逻辑块数据计算出来的;Application Tag 和 Reference Tag 包含该数据块的逻辑地址(LBA)等信息,CRC 校验能够检测出数据是否出错,后者可以保证数据不会出现张冠李戴的情况,比如我 LBA X 使用了 LBA Y 的数据,这种情况往往是 SSD 固件 BUG 导致的,不管怎样,NVMe 总是能够帮你发现这个问题。配备了保镖的数据看起来就是下面的样子(以 512 个字节的数据块为例):

在 Host 和 SSD 的数据传输过程中,NVMe 可以让每个逻辑块数据都带上保镖,也可以让他们不携带保镖,也可以在某些治安差的地方把保镖带上,然后在治安好的地方不用保镖。
Host 往 SSD 写入数据,不带保镖
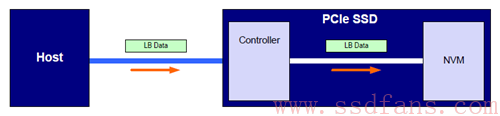
什么情况下可以不带保镖?其实很容易理解,你凡人一个,完全没必要配备保镖,第一你请不起保镖,第二谁有空来伤害你呢?第三太平盛世。反应到 SSD 就是假设你保存的就是一些无关紧要的数据(比如电影什么的),完全灭有必要进行端到端的保护,毕竟数据保护需要传输额外的数据(每一个逻辑数据块都需要携带至少额外的 8 个字节保护信息,有效带宽减少),还有 SSD 需要进行额外的数据完整性校验(耗时,性能变差),最关键的是 PCIe 通道上,其数据天然就能受到保护。怎么说呢?
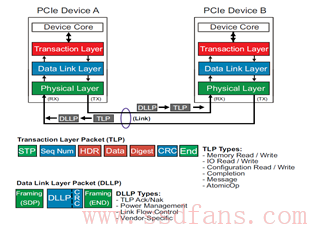
对每个 TLP 来说,其中有个 Digest 域,就是对 HDR 和 Data 进行数据保护的,本质就是 CRC。这个 Digest 是可选的,如果使能了 Digest,数据在 PCIe 上的传输就是毫无风险的,因为有便衣警察的保护,NVMe 在这一层完全没有必要携带保镖了。不过他不能发现张冠李戴的情况,毕竟他的数据完整性校验是通用的,不管你协议内部的逻辑。
Host 往 SSD 写入数据,全程携带保镖
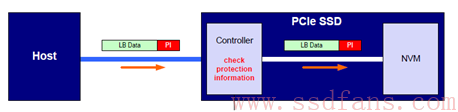
红色的 PI(Protection Imformation)就是传说中的保镖,Host 数据传输通过 PCIe 传输到 SSD 控制器,按道理来讲,数据已经受到了 PCIe 的保护,但是 PCIe 保镖也有可能不在的情况,那就是 TLP 的 Digest 域可能不存在,因为他是可选的,所以不存在也是允许的,这个时候,如果要保证在 PCIe 数据传输的可靠性,那就需要 NVMe 自带保镖。数据到达 SSD 控制器之后,SSD 控制器会重新计算逻辑块数据的 CRC,然后与 PI 中的 CRC 进行比对,如果匹配那就说明数据没有问题,不匹配就是数据传输出错,这个时候 SSD 会向 Host 发出错误报告。除了 CRC 校验之外,还需要检测张冠李戴的情况,通过检测 Reference Tag 和 Application Tag,看看这个没有 CRC 问题的数据是不是该笔 Host 写命令对应的数据,如果不匹配,同样需要向 Host 报错。如果数据检测没有问题,SSD 控制器会把逻辑数据和 PI 信息一同写入到闪存中,这个 PI 写到闪存的意义何在?读的时候意义重大。
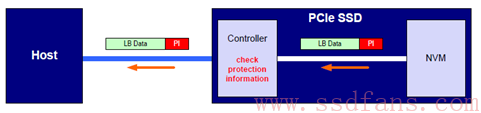
SSD 控制器读闪存的时候,会对读上来的数据进行 CRC 校验,如果写入的时候携带了 PI,这个时候就能检测读上来的数据是否正确,从而决定需不需要将这个数据传递给 Host。有人要说,闪存不是自己存在 ECC 校验吗,为什么还需要额外左一层 PI?没有,闪存是自己存在 ECC 校验,但是 ECC 仅仅保护的是闪存内部数据,从读写流程中,数据在 SSD 内部还需要经过 DRAM 或者 SRAM,这个期间有可能发生比特翻转之类的小概率时间,从而导致数据不正确,所以在 NVMe 层多做一层 CRC 保护就显得有必要了。除了数据在 SSD 内部发生翻转的情况,也有可能由于 SSD 本身固件的原因,出现了张冠李戴的勤情况:数据虽然没有 CRC 错误,但是他并不是Host 所需要的数据。因此,还需要做 Reference Tag 和 Application Tag 检测。除了 SSD 内部会做校验之外,控制器通过 PCIe 传递给 Host 的数据,Host 也会进行相应的校验,看 SSD 返回的数据有没有出错。
Host 往 SSD 写入数据,半程携带保镖
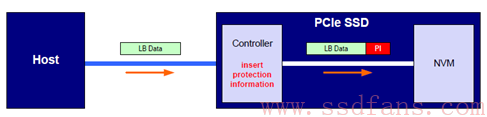
这种情况下,Host 和 SSD 控制器之间没有数据保护,因为 PCIe 已经提供了数据完整性保证了(TLP 中的 Digest 使能),但是在 SSD 内部,控制器和闪存之间,由于搞不清楚的原因(LBA 数据不匹配或者数据翻转等)存在数据错误的可能,NVMe 要求 SSD 控制器把数据写入到闪存前,计算好数据的 PI,然后把数据和 PI 写入到闪存中;SSD 在读取闪存的时候,会对读上来的数据进行 PI 校验,如果没有问题则剥去 PI 信息,然后把逻辑块数据返回给 Host;如果数据存在问题,则 SSD 向 Host 层报错。如图所示:
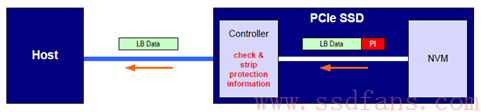
数据的端到端的保护是 NVMe 的一个特色,其本质就是在数据块当中加入 CRC 和数据块对应的 LBA 等冗余信息,SSD 控制器或者 Host 端利用这些信息进行数据校验,然后根据校验结果进行相应的操作。加入这些检测错误信息的好处就是让 Host 与 SSD 控制器及时发现数据错误,副总用就是:
- 每个数据块需要额外的 8 个字节的数据保护信息,有效带宽减少,数据块大小越小,带宽影响越大
- SSD 控制器需要做数据校验,影响性能
但是,与数据的安全性相比,这些副作用的影响都是微乎其微的,这又算得了什么呢?
NVMe 的 Namespace 初步分析
我们都知道,一个 NVMe SSD 子系统由 SSD 控制器、闪存空间以及 PCIe 接口组成,如果把闪存分为一个个独立的逻辑空间,每个空间的逻辑地址从 0 到 N-1(N 是逻辑空间的大小),这样划分出来的一个区域就是一个 Namespace。对于 SATA SSD 来讲,一个闪存空间对应一个 Namespace,而 NVMe SSD 则可以有一个闪存空间对应多个 Namespace。
每一个 NS 都有自己的名字和 ID,就像人有自己的姓名和身份证号一样,而且这个 ID 是独一无二的,系统就是通过这个 NSID 来区分不同的 NS。
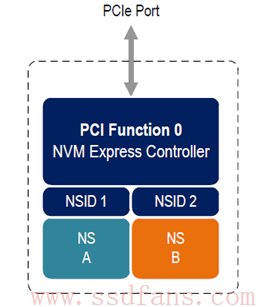
如上图所示的例子,整个闪存空间划分为了 2 个 NS,名字分别为 NS A 和 NS B,对应的 NSID 分别为 1 和 2。如果 NS A 的大小为 M(以逻辑块大小为单位,即扇区大小类似),NS B 大小为 N,则他们的逻辑地址空间分别是 0 到 M-1 和 0 到 N-1。Host 在读写 SSD 的时候,都需要在命令中指定读写的是哪个 NS 的逻辑块。原因很简单,就好比读写逻辑块 0,如果不指定 NSID,SSD 又如何知道该写入 NS A 的 0 地址,还是 NS B 的 0 地址呢?就好比你告诉我你在德州,你不告诉我国家,我怎么知道你在美国德州,还是山东德州呢?
一个 NVMe 的命令大小一共 64 个字节,其中第 4 到 7 个字节指定了要访问的 NS。

对于每一个 NS 来说,都有一个 4KB 大小的数据结构来描述他。
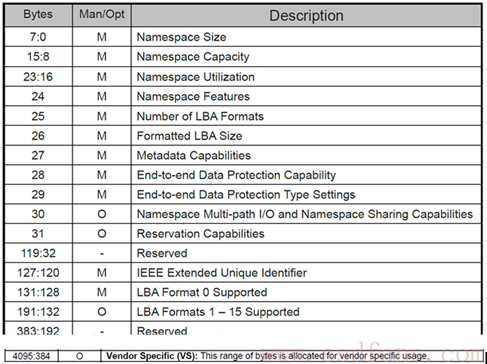
该数据结构描述了该 NS 的大小,整个空间已经写了多少,每个 LBA 的大小,以及端到端数据保护相关的设置,该 NS 是否属于某个控制器还是由几个控制器共享等等信息。NS 由 Host 创建和管理,每一个创建好的 NS,从 Host 的角度来看都是一个独立的磁盘,用户可以在每一个 NS 上做分区等操作。
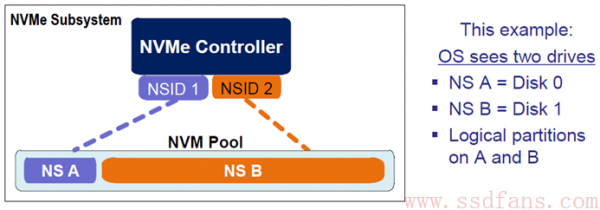
上例中,整个闪存空间划分为了两个命名空间 NS A 和 NS B,操作系统分别看到两个完全独立的磁盘,每个 NS 都是独立的,逻辑块大小可以不同,端到端的数据保护方式可以不同:你可以让一个 NS 使用保镖,另外一个不使用,再一个 NS 半程使用保镖等等设置。这样子,你可以将 SSD 划分为不同的设计,比如一个 NS 使用端到端保护,上面保存操作系统、软件和其他重要数据,另外一个 NS 就不采用端到端的数据保护,上面就存点小电影啥的 ^_^。
其实 NS 更多的应用在于企业级市场,可以根据不同的客户需求创建不同特征的 NS,也就是在一个 SSD 上创建出若干个不同功能特征的磁盘(NS)供不同用户使用。还有一个比较重要的使用场合就是:SR-IOV。
什么是 SR-IOV?英文全称为 Single Root I/O Virtualization,SR-IOV 技术允许在虚拟机之间高效的共享 PCIe 设备,并且他是在硬件设计中实现的,可以获得与本地物理机一样的 I/O 性能。单个 I/O 资源(单个 SSD)可有许多虚拟机共享,从上层虚拟机可以使用自己专用的资源,同时也可以使用共享的通用资源。
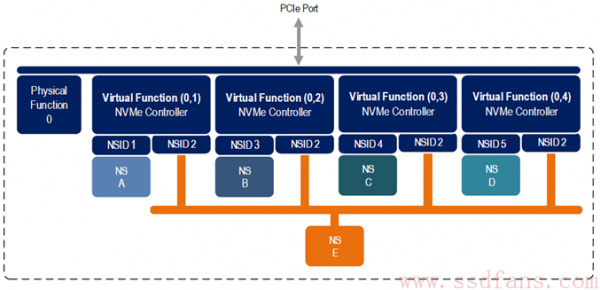
如上图所示,该 SSD 作为 PCIe 的一个 Endpoint,实现了一个屋里功能(Physical Function,PF),有 4 个虚拟功能(Virtual Function,VF)关联该 PF,每一个 VF 都有自己的独享的 NS,还有公共的 NS(NS E)。此功能使得虚拟功能可以共享物理设备,并在没有 CPU 和虚拟机管理程序软件开销的情况下执行 I/O,关于 SR-IOV 的支持,请自行百度或者谷歌,我们在这里只需要知道 NVMe 的 NS 有用武之地即可。
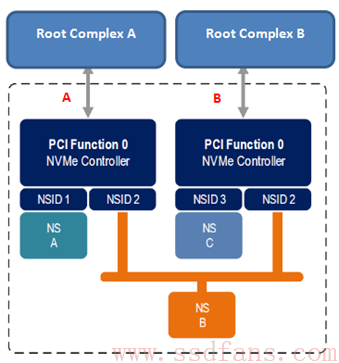
对于 NVMe 子系统来说,除了包含若干个 NS,还可以由若干个 SSD 控制器,注意,这里不是说一个 SSD 控制器有多个 CPU,而是说一个 SSD 上有几个实现了 NVMe 功能的控制器(类似存储的双控概念?那么是不是就需要做数据同步呢,看起来是各干各的,互不产生影响)。
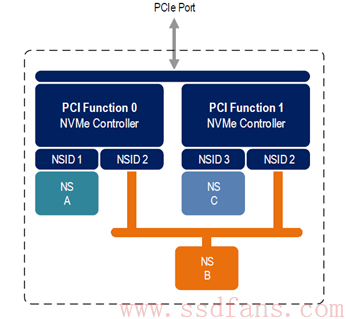
如上图的例子,一个 NVMe 的子系统包含了两个控制器,分别实现了不同的功能(也可以是相同的功能)。整个闪存空间分为了 3 个 NS,其中 NS A 有控制器 0(左边)独享,NS C 由控制器 1(右边)独享,而 NS B 则有两者共享。独享的意思就是只有与之关联的控制器才能访问这个 NS,别的控制器不能访问该 NS,上图中的控制器 0 是无法访问 NS C 的,同样控制器 1 也不能访问 NS A;共享的意思就是该 NS(这里是 NS B)可以被两个控制器共同访问。对于共享 NS,由于几个控制器都可以对他进行访问,所以要求每个控制器对该 NS 的访问都是原子操作,只有这样才能避免同步操作。
事实上,一个 NVMe 子系统,除了可以有若干的 NS 以及若干个控制器之外,还可以有若干个 PCIe 接口。

与前面的架构不一样,上图的架构是每一个控制器自己独立拥有一个 PCIe 接口,而不是两者共享一个。Dual Port,这东西可是在 SATA SSD 上是不曾存在过的。这两个接口可能连着同一个主机,也可能连接不同的主机。不过现在能提供 Dual Port 的 SSD 接口只有 SFF-8639(关于这个接口,请参考文章 SFF-8639接口来袭,也叫 U.2,它支持标准的 NVMe 协议和 Dual-Port,是 SSD 接口的明日之星。

下图就是两个 PCIe 接口连着一个主机的情况:
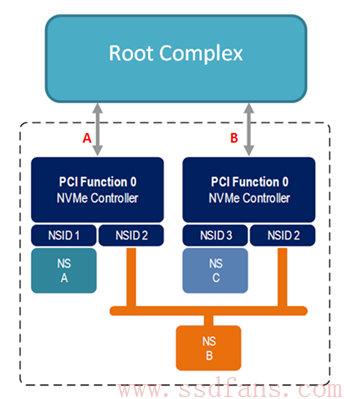
为什么要这么玩呢?我认为,一方面 Host 访问 SSD 可以双管齐下,性能可能会更好一点。不过由于对共享 NS 只能是原子操作,那么应该用处不大,可能是能够同时访问 NS A 和 NS C 吧。另外一个方面就是冗余设计,这样可以提高系统的稳定性,假设 PCIe A 接口出现问题,这个时候 Host 可以通过 PCIe B 继续对 SSD 进行访问,当然,独享的 NS A 还是访问不了了。
如果 Host 突然死机怎么办?在一些严苛的环境下,不允许发生任何宕机情况,但是电脑总是会死机的,怎么办呢?最直接的方式就是采用冗余容错策略:SSD 有两个控制器,有两个 PCIe 接口,那么我主机也弄个双主机(一个挂了,另外一个接管任务继续执行,然后主机 1 就慢慢重启吧)。
我们来看一个 Dual Port 的真实产品,2015 年,OCZ 发布了业界第一个具有 Dual Port 的 PCIe NVMe 的 SSD:Z-Drive 6000 系列产品。

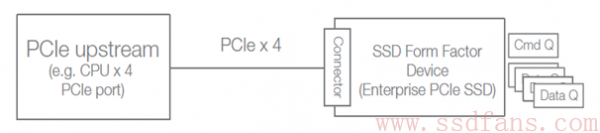
物理上,这些 SSD 都有两个 PCIe Port,但是可以通过不同的固件,实现 Single Port 和 Dual Port 的功能,如果只用一个 Port,那么他就是一个 4 通道的 PCIe 接口,向上连接一个主机:
如果使能 Dual Port,那么可以配置为 2 个 2 通道的 PCIe 接口,即每一个 Port 两个通道:
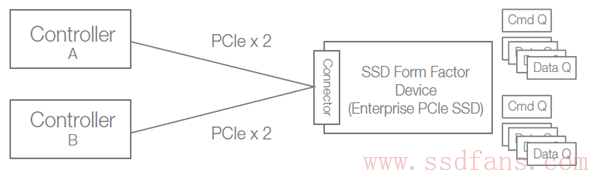
具体来看,整个系统就是这个样子的:

每个 Port 可以连接两个独立的 Host,Host 有两个独立的数据通道(Data Path)对闪存空间进行访问,如果其中一个数据通道发生故障,OCZ 的 Host 热交换(Hot-Swap)技术能让另外一个 Host 无缝低延时的接管工作,有些应用,比如银行的金融系统、在线交易处理(OnLine Transaction Processing,OLTP)、在线分析狐狸(OnLine Analytical Processing OLAP)、高性能计算(Hign Performance Computing HPC)、大数据等对系统可靠性和实时性要求非常的搞,这个时候,带有 Dual Port 的 SSD 就能派上用场。
当然,个人而言,这些带了 Dual Port 的 SSD 用处不大,他的设计出现也是为了满足以上描述的企业用户需求。
多 NS、多控制器、多 PCIe 接口就是整个 NVMe 的理念,它给了 NVMe 开发者和架构师很大的自由发挥的空间,给不同的 NS 配置不同的数据保护机制,或者虚拟化技术,或者冗余容错技术等等,至于能做成什么,就看你自己的想象力了。
本篇文章主要技术资料来自 SSDFans 站蛋蛋读 NVMe 的系列文章,增加了个人理解并做了部分分析记录与此。