NUMA_NO_NODE 在内核中的作用
最近在研究 NUMA Node 对于内存申请的影响,发现有一些网卡驱动会去主动探测其网卡设备所在的 PCIe 节点所在的 NUMA Node,然后通过 alloc_pages_node 去该节点附近进行内存申请。理论上来说,这种方式比较好,也是麒麟内核在做网络优化时常用的一种手段之一,但是这种手段难道就没有弊端了吗?
不是没有,通过 alloc_pages_node 捆绑某一个节点之后,无论核外程序如何迁移,内核中网络队列都只会在 PCIe 网卡所在的附近申请内存,如果涉及到从核外拷贝数据到核内,那么这期间的延时是非常大的,例如
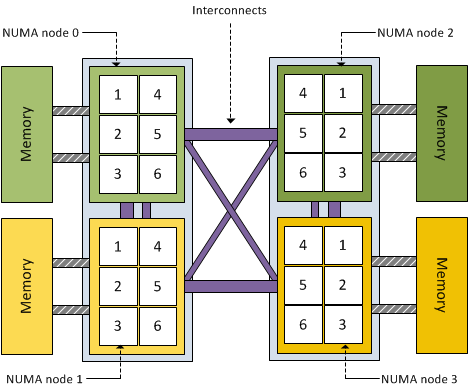
可以看到,跨 NUMA 节点之间拷贝内存需要通过高速级联总线进行数据迁移,可想而知,效率肯定低于在 Node 内进行数据拷贝,当然,为了解决这一个问题,只能继续将核外的网络程序,例如 iperf 或者 netperf 程序也绑定到同一个 Node,这样,内核和核外都在一个 node,且 PCIe 设备也挂载在本 Node,这就是效率最佳的时刻。
既然如此,那么不是皆大欢喜吗?
如果仅仅这么简单确实很欢喜,但是举个例子说,飞腾 arm64 芯片一共 64 个核,8 个 Node,如果按照上文的说法,那么最佳性能就只能把所有的运行都挂载 0 号 Node(PCIe 挂载此处),剩下的 56 个 CPU 难道要围观吗?这就是问题。
于是,有一次和华为的 HNS3 网卡驱动开发工程师在进行技术探讨的时候,聊到了 alloc_pages_node 这个接口,以及 NUMA_NO_NODE 的功效,刚开始我们都没有特别注意这个定义在内存申请的作用,后来一直也没有去查,直到今天,决定来认真看看他到底如何工作。
直接进入 alloc_pages_node 的接口实现代码:
/*
* Allocate pages, preferring the node given as nid. When nid == NUMA_NO_NODE,
* prefer the current CPU's closest node. Otherwise node must be valid and
* online.
*/
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
if (nid == NUMA_NO_NODE)
nid = numa_mem_id();
return __alloc_pages_node(nid, gfp_mask, order);
}
很明显,如果给的是 NUMA_NO_NODE 的话,nid 就会重新去获取,那么 numa_mem_id 又是如何实现的:
/* Returns the number of the nearest Node with memory */
static inline int numa_mem_id(void)
{
return numa_node_id();
}
static inline int numa_node_id(void)
{
return cpu_to_node(raw_smp_processor_id());
}
很清晰了,其实如果你在 kmalloc 时,输入的是 NUMA_NO_NODE,那么内核会自动探测当前正在运行的 CPU 所在的 Node,然后在该 Node 上进行内存分配。