io_uring(2)- 从创建必要的文件描述符 fd 开始
Contents
说在前面的废话
本章开始,我会深入代码进行分析,逐步的剖析最新版本(5.3 版本)的 io_uring 代码实现逻辑1,内核代码并不是那么容易就描述得清晰的,每一个小小的判断或者小小的 flag 都有自己的历史,最终导致的就是代码逻辑上晦涩难懂,尤其是没有从原始代码开始理解的小伙伴,看到最终的状态就会是:我擦,这是为什么?这特么的又是为啥要搞一下?如果你没有发出这样的感叹,除非两类人,第一类就是完全搞懂了这些代码逻辑,了解他的历史渊源;还有的就是,不懂装懂还不问的人。
看不懂代码没有什么值得羞耻的,我经常性的看不懂一些代码,然后大骂作者傻 B 为何要这么设计,然后又继续看,同时会去寻找内核中相同的设计的逻辑代码以及查找 git log,分析当时作者提交这一行代码时的心态,于是就会开始慢慢的理解为何需要这么设计。通过多年的摸爬滚打得出的基本结论就是,看似奇葩的设计多数就是为了解决死锁问题和性能问题,死锁问题就自不必说,不解决可不行,搞不懂为何死锁也就无法去理解这段代码,为何死锁?看看提交记录,一般都会告诉你会在什么情况下会死锁,以及死锁情况下的 CPU 运行栈,你对着堆栈大概就可以在脑海中模拟出死锁时的状态,然后再通过状态去模拟解决方案,这样代码就可以更容易理解了。
另外一个就是性能问题,其实很多时候这不是叫做性能问题,应该叫做性能优化补丁,有一些看似奇怪的代码是为了加速推进内核代码逻辑的执行,且尽可能的减少锁的存在,最好是实现无锁的状态。要理解这样的代码也不难,只要你认可他是为了实现优化性能而存在,那么再往这个方向去思考,很快就会发现优化点在何处,这类代码理解不难,难的是很难写出来,这需要作者拥有大量的代码编程经验以及性能优化经验,目前我还达不到这个能力,不过能学习前辈们的优秀经验自然是极好的。
这里我废话一大堆的意思就是鼓励各位自行去查看 fs/io_uring.c 的代码,当你开始领会之后代码意图时会理解我写这段时的感受,从本章开始聚焦一个个小的知识点,以小见大的形式开始完整的描述整个驱动的实现。
从系统调用 io_uring_setup 说起
io_uring 作为异步 IO 的其中一员,首先需要创建一个 context 用来管理整个会话,基本上创建完成之后,就会返回一个 fd,这个 fd 就是交给核外程序使用的文件描述符,一切的一切都是从这个 fd 开始,当然,核外是采用的是 fd,而内核则需要一大堆的数据用来支撑这个 fd 以便实现足够强大的能力,于是 io_uring_setup 系统调用就提供了这样的能力。
SYSCALL_DEFINE2(io_uring_setup, u32, entries,
struct io_uring_params __user *, params)
{
return io_uring_setup(entries, params);
}
这是标准的系统调用实现方案,从实现上来看,这是一个需要传递两个参数的系统调用2,一个是 entries,用来表示提交的整个缓存区数组的大小3,而 params 这个参数有一部分是核外传递给核外的,比如 params->flags,这个成员变量是用来设置当前整个 io_uring 的标志的,他将决定是否启动 sq_thread,是否采用 iopoll 模式等等,这些都是在创建阶段就决定了;还有一部分是用来自内核传递数据到核外的,比如 sq_ring->ring_mask 等。
交互需要使用的缓存区
上段提到了缓存区,真正的概念并不能叫做一个缓存区,他是一个内存映射区域。为何这样讲,记得上一篇文章《我们为何需要 io_uring》讲到要实现核外内核的一个零拷贝,最佳的方式就是大家公用一块内存,核外往这段内存写数据,然后通知内核使用这段内存数据,或者内核填写这段数据,核外使用这部分数据。如果有 VIRTIO 的经验就可以将它很快的理解,如果没有的话,我继续深入的剖析。
到底需要映射几块内存区域
为了实现零拷贝,于是我们需要缓冲区,那么需要几块这样的缓存区呢?至少需要两块,一块用于核外传递数据给内核,一块是内核传递数据给核外,也就形成了一方只读,一方只写的情况,这样带来的好处是什么呢?没错,那就是无锁设计,通过几个简单的头尾指针的移动就可以实现快速交互。那么他们分别需要保存的是什么数据呢?其实很简单的理解,我们假设 A 缓存区为核外写,内核读,那么对于 io_uring 这个框架而言,它相当于是将 IO 数据写到这个缓存区,然后通知内核来读;再假设 B 缓存区为内核写,核外读,他所承担的责任就是返回完成状态,标记 A 缓存区的其中一个 entry 的完成状态为成功或者失败等等信息。于是,这就是 io_uring 中提到的 sq_ring 和 cq_ring,是不是了解了他们的由来。
如果是上面的东西你已经理解了,那么不好意思,我要继续否定你的观念,没错,理论上的设计我们只需要映射两块内存即可,但是不好意思,我们的 sq_ring 这个环又被拆分了两个单独的部分,一个仍然是叫做 sq_ring,他承担的是对 sq 的一个管理,包含了头尾指针以及其他管理元数据,而核外往内核发送的 entry 部分,单独切分了一个叫做 sqes 的一块独立内存。于是现在一个简单的 io_uring 的 fd 需要映射三块独立的内存,这些内存是内核和核外都需要共享处理的,他们之间还存在很多的关联,其实也不算特复杂,通过图来展示:
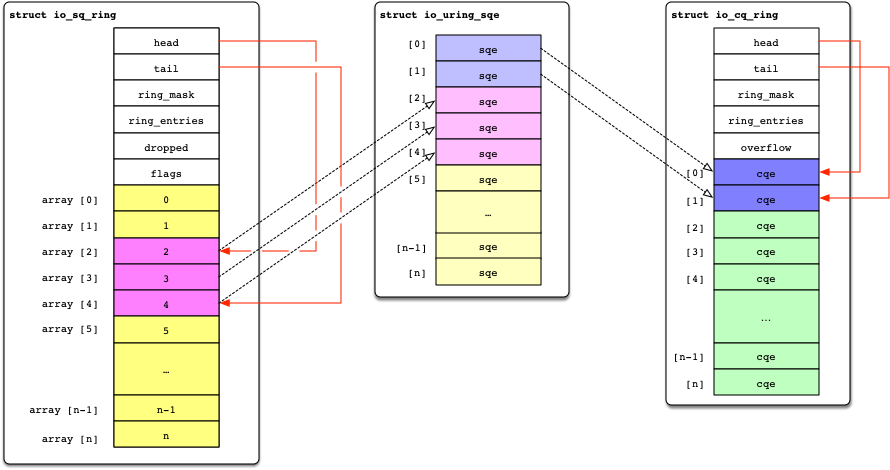
为什么需要拆分 sq_ring
为什么需要这样设计呢?我希望你也和我一样,对这种问题提出疑问,只不过 Jens 的设计文档很好的给到了我答案:
For the submission side, the roles are reversed. The application is the one updating the tail, and the kernel consumes entries (and updates) the head. One important difference is that while the CQ ring is directly indexing the shared array of cqes, the submission side has an indirection array between them. Hence the submission side ring buffer is an index into this array, which in turn contains the index into the sqes. This might initially seem odd and confusing, but there's some reasoning behind it. Some applications may embed request units inside internal data structures, and this allows them the flexibility to do so while retaining the ability to submit multiple sqes in one operation. That in turns allows for easier conversion of said applications to the io_uring interface.
他说的很清楚了,话虽然很容易读懂,但是具体的 example 我是没见到,所以对于给出的理由我还是没有完全理解,或许下一次可以看到一个如上所言的例子,才会加深对这段话的理解。
关键数据结构
sq_ring 数据结构
struct io_uring {
u32 head ____cacheline_aligned_in_smp;
u32 tail ____cacheline_aligned_in_smp;
};
/*
* This data is shared with the application through the mmap at offset
* IORING_OFF_SQ_RING.
*
* The offsets to the member fields are published through struct
* io_sqring_offsets when calling io_uring_setup.
*/
struct io_sq_ring {
/*
* Head and tail offsets into the ring; the offsets need to be
* masked to get valid indices.
*
* The kernel controls head and the application controls tail.
*/
struct io_uring r;
/*
* Bitmask to apply to head and tail offsets (constant, equals
* ring_entries - 1)
*/
u32 ring_mask;
/* Ring size (constant, power of 2) */
u32 ring_entries;
/*
* Number of invalid entries dropped by the kernel due to
* invalid index stored in array
*
* Written by the kernel, shouldn't be modified by the
* application (i.e. get number of "new events" by comparing to
* cached value).
*
* After a new SQ head value was read by the application this
* counter includes all submissions that were dropped reaching
* the new SQ head (and possibly more).
*/
u32 dropped;
/*
* Runtime flags
*
* Written by the kernel, shouldn't be modified by the
* application.
*
* The application needs a full memory barrier before checking
* for IORING_SQ_NEED_WAKEUP after updating the sq tail.
*/
u32 flags;
/*
* Ring buffer of indices into array of io_uring_sqe, which is
* mmapped by the application using the IORING_OFF_SQES offset.
*
* This indirection could e.g. be used to assign fixed
* io_uring_sqe entries to operations and only submit them to
* the queue when needed.
*
* The kernel modifies neither the indices array nor the entries
* array.
*/
u32 array[];
};
正如前一节描述的,sq_ring 拆分之后,使用的是 array 的零长度数组来指向 sqes 的另外一块内存区域,数据结构的描述都很详细,没有需要特别说明的地方。
cq_ring 数据结构
struct io_cq_ring {
/*
* Head and tail offsets into the ring; the offsets need to be
* masked to get valid indices.
*
* The application controls head and the kernel tail.
*/
struct io_uring r;
/*
* Bitmask to apply to head and tail offsets (constant, equals
* ring_entries - 1)
*/
u32 ring_mask;
/* Ring size (constant, power of 2) */
u32 ring_entries;
/*
* Number of completion events lost because the queue was full;
* this should be avoided by the application by making sure
* there are not more requests pending thatn there is space in
* the completion queue.
*
* Written by the kernel, shouldn't be modified by the
* application (i.e. get number of "new events" by comparing to
* cached value).
*
* As completion events come in out of order this counter is not
* ordered with any other data.
*/
u32 overflow;
/*
* Ring buffer of completion events.
*
* The kernel writes completion events fresh every time they are
* produced, so the application is allowed to modify pending
* entries.
*/
struct io_uring_cqe cqes[];
};
可以看得出来,cq_ring 自我包含了 cqes,而不是拆分开来,各自的段也都描述得很清晰,没有特别需要解释的。
sqes 的单元数据结构
struct io_uring_sqe {
__u8 opcode; /* type of operation for this sqe */
__u8 flags; /* IOSQE_ flags */
__u16 ioprio; /* ioprio for the request */
__s32 fd; /* file descriptor to do IO on */
__u64 off; /* offset into file */
__u64 addr; /* pointer to buffer or iovecs */
__u32 len; /* buffer size or number of iovecs */
union {
__kernel_rwf_t rw_flags;
__u32 fsync_flags;
__u16 poll_events;
__u32 sync_range_flags;
};
__u64 user_data; /* data to be passed back at completion time */
union {
__u16 buf_index; /* index into fixed buffers, if used */
__u64 __pad2[3];
};
};
也很简单,这就是核外往内核填写的 entry 的数据结构,准备好这样的一个数据结构,将它写到对应的 sqes 所在的内存位置,然后再通知内核去对应的位置取数据,这样就完成了一次数据交接。
这样的一个 entry 的大小的固定的,不知道会不会有小伙伴注意到然后问不是说好的核外写数据到缓冲区然后内核来取吗?嗯,没错,如果你想到了这一点说明你在想问题,虽然没有说对,但是你思考了。确实,前文说的确实是核外写数据到缓冲区,然后内核来读,不过你换个角度来想,我写到这个共享内存区域的只是你要填写的数据的内存起始地址以及长度,不也是可以找到最终的数据位置吗?而且这样带来的好处是两个方面:第一,不论你核外写的数据长度是多少,我的 entry size 都是固定的,因为只需要传递 addr 和 len 给内核;第二,很多时候,核外是自己在其他地方产生好了的一个 buffer 数据,最终需要交到内核,如果你需要再填写一份共享的缓冲区,岂不是又需要从这个 buffer 中拷贝到共享缓存区?这就是我稍微补充的一点,其实在内核中这样的设计随处可见,见多了就一眼能够明白,拿出来讲也只是为了降低阅读门槛,让接触内核少的小伙伴也能理解到什么是 io_uring 这个神奇的框架。
cqes 的单元数据结构
struct io_uring_cqe {
__u64 user_data; /* sqe->data submission passed back */
__s32 res; /* result code for this event */
__u32 flags;
};
cqes 的单元项就简单得多,user_data 就是 sqe 发送时核外填写的,只不过在完成时回传而已,res 就是用来保存最终的这个 sqe 的执行结果,可以是成功也可以是失败等等。flags 这个参数目前还没有用到,忽略。
最核心的 io_ring_ctx
前面介绍了 sqe/cqe/sq_ring/cq_ring 等关键的数据结构,他们是用来承载数据流的关键部分,有了数据流的关键数据结构我们还需要用到一个最为核心的数据结构,也就是用来做整个 io_uring 控制流的 struct io_ring_ctx。
struct io_ring_ctx {
struct {
struct percpu_ref refs;
} ____cacheline_aligned_in_smp;
struct {
unsigned int flags;
bool compat;
bool account_mem;
/* SQ ring */
struct io_sq_ring *sq_ring;
unsigned cached_sq_head;
unsigned sq_entries;
unsigned sq_mask;
unsigned sq_thread_idle;
struct io_uring_sqe *sq_sqes;
struct list_head defer_list;
} ____cacheline_aligned_in_smp;
/* IO offload */
struct workqueue_struct *sqo_wq;
struct task_struct *sqo_thread; /* if using sq thread polling */
struct mm_struct *sqo_mm;
wait_queue_head_t sqo_wait;
struct completion sqo_thread_started;
struct {
/* CQ ring */
struct io_cq_ring *cq_ring;
unsigned cached_cq_tail;
unsigned cq_entries;
unsigned cq_mask;
struct wait_queue_head cq_wait;
struct fasync_struct *cq_fasync;
struct eventfd_ctx *cq_ev_fd;
} ____cacheline_aligned_in_smp;
/*
* If used, fixed file set. Writers must ensure that ->refs is dead,
* readers must ensure that ->refs is alive as long as the file* is
* used. Only updated through io_uring_register(2).
*/
struct file **user_files;
unsigned nr_user_files;
/* if used, fixed mapped user buffers */
unsigned nr_user_bufs;
struct io_mapped_ubuf *user_bufs;
struct user_struct *user;
struct completion ctx_done;
struct {
struct mutex uring_lock;
wait_queue_head_t wait;
} ____cacheline_aligned_in_smp;
struct {
spinlock_t completion_lock;
bool poll_multi_file;
/*
* ->poll_list is protected by the ctx->uring_lock for
* io_uring instances that don't use IORING_SETUP_SQPOLL.
* For SQPOLL, only the single threaded io_sq_thread() will
* manipulate the list, hence no extra locking is needed there.
*/
struct list_head poll_list;
struct list_head cancel_list;
} ____cacheline_aligned_in_smp;
struct async_list pending_async[2];
#if defined(CONFIG_UNIX)
struct socket *ring_sock;
#endif
};
io_ring_ctx 是贯穿整个 io_uring 所有过程的数据结构,基本上在任何位置只需要你能持有该结构就可以找到任何数据所在的位置,这也就是前文所说的核外围绕 fd 做文章,而内核为了服务好 fd 而对应出一个 context 结构。
io_uring 创建的执行逻辑
介绍完数据结构以及前面的其他废话之后,终于到了最最重要的逻辑实现了,不管数据结构设计如何,都需要合适的逻辑来配合这个数据结构,于是我画了一个简单的逻辑图:
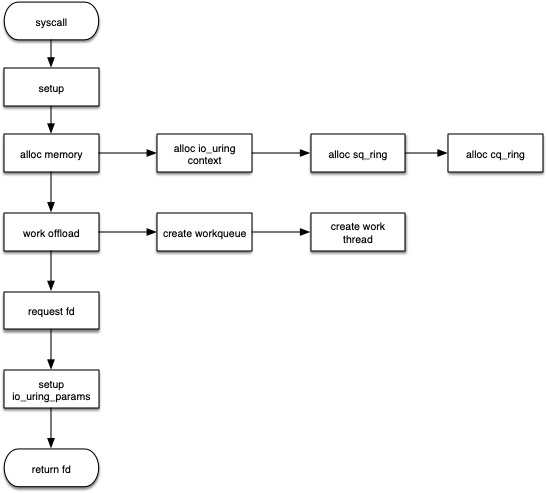
很简单是不是,没错就是这么简单,当你准备好这些数据结构之后,你就发现,创建的过程就是初始化好这些数据结构,建立好对应的缓存区,然后通过系统调用的参数 struct io_uring_params *p 传递回去,告诉核外你的环内存地址在哪,起始指针的地址在哪等等关键的信息。
struct io_sqring_offsets {
__u32 head;
__u32 tail;
__u32 ring_mask;
__u32 ring_entries;
__u32 flags;
__u32 dropped;
__u32 array;
__u32 resv1;
__u64 resv2;
};
/*
* sq_ring->flags
*/
#define IORING_SQ_NEED_WAKEUP (1U << 0) /* needs io_uring_enter wakeup */
struct io_cqring_offsets {
__u32 head;
__u32 tail;
__u32 ring_mask;
__u32 ring_entries;
__u32 overflow;
__u32 cqes;
__u64 resv[2];
};
/*
* io_uring_enter(2) flags
*/
#define IORING_ENTER_GETEVENTS (1U << 0)
#define IORING_ENTER_SQ_WAKEUP (1U << 1)
/*
* Passed in for io_uring_setup(2). Copied back with updated info on success
*/
struct io_uring_params {
__u32 sq_entries;
__u32 cq_entries;
__u32 flags;
__u32 sq_thread_cpu;
__u32 sq_thread_idle;
__u32 resv[5];
struct io_sqring_offsets sq_off;
struct io_cqring_offsets cq_off;
};
这里需要特别强调的是,如果你有好好审视 io_uring_params 的数据结构就会发现,内核返回的并不是环的内存地址,而是 offset。Why?这又是一个全新的设计,我的天啊到处都是没有见过的设计,只能说明咱们水平还不够。
其实很好理解,setup/create 并不是 mmap,这里返回的不是内存地址,而是各个数据结构的成员距离映射区域内存的起始地址位置偏移 offset,核外可以通过 mmap 分别获取到这三块核内核外共享的内存区域起始地址(create 的时候就分配好了),然后再通过 io_uring_params 得到的各成员距离起始地址的 offset 就能得到该成员自己的实际地址,然后再访问这个地址就能得到它上面的数据。
结束语
整个 io_uring 的创建其实是比较简单的流程,只不过在这个过程中顺带介绍了各个数据结构的组成以及使用,总的来说,虽然 io_uring 使用到了很多新的概念,其实这些新的概念很多都已经通过了其他方面的佐证表示这个方案可行,比如 io_uring 本身这个方案和 VirtIO 有很多相似之处,其次 io_uring 的很多设计逻辑,比如 poll 的代码是基本上直接来自 aio 的模块,已经在 aio 上得到了充分的验证(也不能算特别充分,毕竟 2018 年才集成)。接下来的章节会一一的介绍更多的单元实现逻辑,以便能够完全理解 io_uring。
最后再写一个小的技巧,这也是我自己遇到的一个,然后发邮件问 Jens Axboe 的问题,看了 io_uring 的代码就会质疑已经有了 sq_ring->ring_mask/cq_ring->ring_mask 了之后,为何在 ctx 中还需要定义一个 sq_mask 和 cq_mask,在代码中直接使用 sq_ring->ring_mask 和 cq_ring->ring_mask 不就可以了吗? 然后就给我回了邮件如下:
We could, but we cache it in the kernel since the ring value could potentially be modified by the application
所以说,有问题有直接问,尽管有可能作者并不会鸟你,但是并不妨碍你问,也许回答了呢?