Linux 内核 Buddy 系统
目录
Linux 的内存管理部分很复杂,涉及到了方方面面的原理,众所周知 Linux 内核由全世界各个地区的优秀工程师集智而成,所以这里面包含了许许多多的令人赞叹的设计,今天我们要来学习的伙伴系统就是这其中的臻品之一。在内核初始化完成之后,所有的内存申请与释放都交给了伙伴系统来完成,他就像是一个厨师,总是很勤劳的买菜、洗菜做饭等等,而且不论客人如何对待他,他也总是笑脸相迎,默默付出不求回报,等待着客人用餐完毕之后,他也总是辛劳的收拾残局。
Linux 内核使用二进制伙伴算法来管理和分配物理内存页,该算法由 knowlton 设计,伙伴系统是一个采用 2 的幂次方的分配器以及空闲缓冲区合并的内存分配方案,基本思想很简单。内存被分为了很多页面的大块,当然,这些大块都是以 2 的幂次方个页,当申请内存的时候,首先去寻找所申请的内存页大小匹配空闲块,找到了则直接返回该物理页地址,若没有相匹配的空闲页则将更为大的块切割一小块分配出去,分配完成之后,分配出去的块与剩下的部分则形成了一个伙伴关系,当最终分配出去的块被释放之后,其伙伴会被检测出来,如果伙伴也空闲则合并这二者形成一个大块。
伙伴系统结构
伙伴系统数据结构
系统内存中的每一个物理页,都对应一个 struct page 的实例,每个内存域都关联一个 struct zone 的实例,其中保存了用于管理伙伴数据的主要数据结构数组:
struct zone {
/* free areas of differents sizes */
struct free_area free_area[MAX_ORDER];
};
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
struct free_area 是一个伙伴系统的辅助数据结构:
| 字段 | 描述 |
|---|---|
| free_list | 用于连接空闲页的链表,页链表包含大小相同的连续内存区域 |
| nr_free | 指定当前内存去中空闲页块的数量 |
伙伴系统的分配器维护着空闲页面组成的块,每一个块都是一个 2 的幂次方个页,指数为阶。阶是伙伴系统一个很重要的术语,他被用来描述内存分配的数量单元,比如两个页就是 21,4 个页就是 22,这其中的 1 和 2 就是阶,以此类推可以到达 MAX_ORDER。zone->free_area[MAX_ORDER] 数组中阶作为各个元素的索引,用来对应链表中的连续内存块包含的页面数量。我们来看看一个示意图,索引 0 指向的链表就是 20 阶链表,他携带的内存块都是 1 个页面,再比如 24 这个位置链表就是表示他下面挂的都是 64 个页大小的连续内存块,那么他的字节数为 256K。
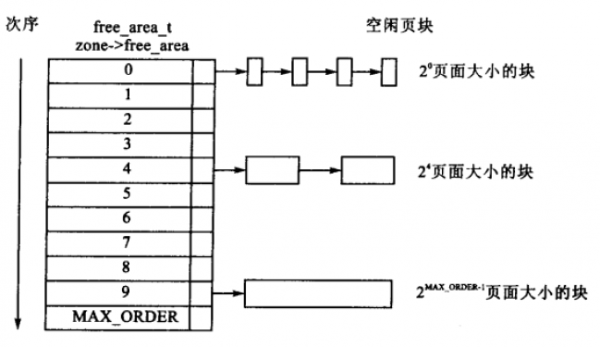
最大阶 MAX_ORDER 和 FORCE_MAX_ZONEORDER
一般的情况下,MAX_ORDER 的值为 11,这意味着当前的 Linux 内核的最大连续内存块为 211 也就是 2048 个页,换算为字节就是 8M。定义参见:include/linux/mmzone.h?h=v4.15.15#n23
/* Free memory management - zoned buddy allocator. */
#ifndef CONFIG_FORCE_MAX_ZONEORDER
#define MAX_ORDER 11
#else
#define MAX_ORDER CONFIG_FORCE_MAX_ZONEORDER
#endif
#define MAX_ORDER_NR_PAGES (1 << (MAX_ORDER - 1))
当然的,这个最大阶是可以通过配置文件自定义的,例如在 ARM64 的机器上,配置文件直接给出了建议:
config FORCE_MAX_ZONEORDER
int
default "14" if (ARM64_64K_PAGES && TRANSPARENT_HUGEPAGE)
default "12" if (ARM64_16K_PAGES && TRANSPARENT_HUGEPAGE)
default "11"
对于普通用户来讲,不要随意修改最大的阶数,默认采用内核 default 值即可满足需求,除非你知道自己在做什么。
内存块是如何链接到一起的
从 struct zone 的 free_area 结构体数组内的 free_list 可以得知,这个数组保存的是一个链表的头,所以他其实指向的是一个完整的链表,根据这个数组的索引可以得知,这个链表下面挂载的都是 2x 方个数的连续页面,每一个 free_list 项表示的是一个连续的物理内存块,这样管理起来很简单而且开销不大。具体实现如图所示:
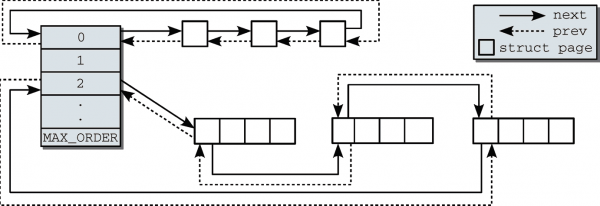
从图中可以得出不同大小的连续页面块都是挂载在不同的链表上,当低阶连续页面不足时,就会从比他高一阶的链表中切出一半分离1,剩下的一半就会自动匹配到对应的链表挂载起来。这里不需要标记划走的部分内存和剩余的内存的关系,因为都被划走的内存释放时,会主动判断他的地址与空闲链表中的页面是否可以合并,也就是判断是否为伙伴,如果可以合并,那么就会被合并起来,然后移交到高一阶链表。
上面的图仅仅表示的一个 zone 下面的内存管理方案,对于 NUMA 机器来讲,他是分为多个域的,每一个域都各自保留一个类似的伙伴系统分配器,类似 DMA 和 ZONE_HIGHMEM 这样的特殊域也是各自管理伙伴分配器的,但是对于系统来讲整个内存是一体的,所以他们需要进一步的关联起来,来看一张图,可以比较清晰的看出整体的内存时如何分配的。
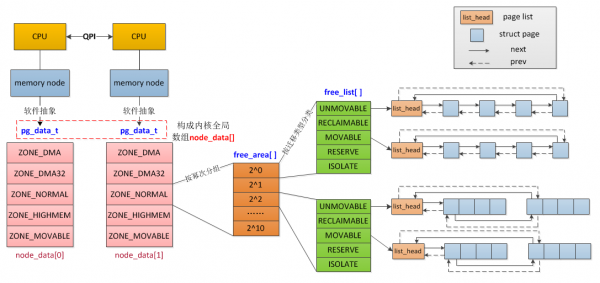
内存节点(NODE)
内存节点是由在 NUMA 架构的计算机系统下,同一个 CPU 下的一片连续物理内存组成的,在内核中使用pg_data_t来进行一个抽象。
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
struct page *node_mem_map;
unsigned long node_start_pfn;
unsigned long node_present_pages;
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd; /* Protected by lock_memory_hotplug() */
} pg_data_t;
pg_data_t 描述了整个 Node 的基本信息:
| 字段 | 备注 |
|---|---|
| node_zones | 表示当前 node 包含的 zones |
| node_zonelists | 该 node 的备选节点及内存域列表 |
| node_mem_map | Linux 为每一个物理页分配一个 struct page 的管理结构体,并且形成一个结构体数组,node_mem_map 就是这个结构体数组的指针;pfn_to_page 和 page_to_pfn 都是借助该数组实现 |
| node_start_pfn | 该 node 的起始页帧号 |
| node_present_pages | 该 node 上所有的物理 page 的数量 |
| node_spanned_pages | 该 node 地址范围内所有的 page 数量,包括空洞 |
| kswapd | 负责回收该 node 内存的内核线程,每一个 node 对应一个内核线程 kswapd |
在 NUMA 系统下,每一个节点都是一个 pg_data_t 的结构体来描述他下面的内存,而对于 UMA 系统而言,他的 NODE_ID 一直都是 0,所以他也是采用这种方式进行内存管理,为了能够快速的访问到整个系统的内存,内核在全局区域维护一个 node_data[] 的指针数组,根据给定的 NODE_ID 即可快速的查找到需要的内存所在的位置。
内存域 Zone 的价值
虽然前文基于 Buddy 系统简要描述了 struct zone 的基本情况,此处仅仅阐述一下 zone 的不同段的价值。为了一些特殊的应用场景(比如 ISA 设备的 DMA 只能访问前 16M;kmalloc 只能分配低端内存)因此内核又需要将 node 分为 zone。zone 的划分已经在上一篇Linux 内存布局中进行了详细介绍,这里就不进行阐述。
Zone 的内存“价值”是有所分别的,在内存进行回收的时候,按照分配的“廉价度”依次为:ZONE_HIGHMEM > ZONE_NORMAL > ZONE_DMA。高端内存时很廉价的,因为内核没有任何部分是一定依赖该区域分配,如果高端内存耗尽也不会影响到内核,这也是高端内存优先分配的原因。普通内存区域则有所不同,因为所有的内核数据都保存在该段,如果该段资源紧张则有可能导致内核崩溃等。DMA 区域是最为昂贵的,因为他不但数量少很容易被耗尽,而且被用于与外设进行 DMA 交互,一旦失去则丧失与外设的交互能力。
备选节点极其内存域列表(node_zonelists)
从前面的分析可以得知,zone 是进行内存分配的基本容器,既然是容器,那么容量总是有限的,那么当他容量不够导致申请失败的时候,又该怎么办呢?这就是要介绍到的 node_zonelists 所要发挥的作用。node_zonelists 定义了一个 zone 的搜索列表(每一项代表一个 zone)当其中的某一个 node 的某个 zone 申请内存失败的时候,就会搜索该表,查找一个合适的 zone 继续进行内存分配。现在通过一个简单的例子对这个概念进行解释,假设某 NUMA 系统存在 4 个内存节点 ABCD,他们分别包含 ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM,以 0,1,2 分别表示。他的模型如下:
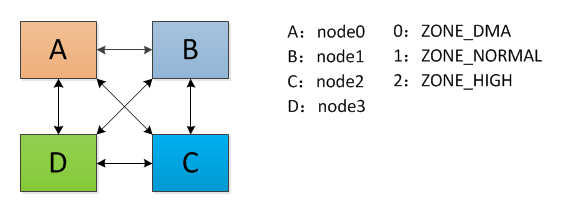
按照 node 进行失败后内存申请排序:优先选择距离较近的 node,然后在选择比较廉价的 zone 进行内存分配,那么他的 node_zonelists 如图所示:

或者

按照 zone 廉价程度进行失败后内存申请排序: 优先选择比较廉价的 zone,再选择距离最近的 node,那么他的 node_zonelists 如下图所示:

或者

为何会存在两个不同的列表?主要是因为 A 到 B 的距离可能等于 A 到 D 的距离(这很有可能)。
- 为何是一半?因为高一阶的连续内存块大小是低一阶的 2 倍,这是设计决定的,当然,如果高一阶也没有内存可以申请的话,就需要继续往更高阶链表申请。 ↩︎