Linux 内核双向链表
Contents
双向链表在内核中是一个非常常见的存在,从数据的关联,队列的创建,每一个子系统中,都有他的影子存在,它属于内核最基本的一个部件。那么他虽然是非常的常见,但是要弄清楚他也不是那么容易,因为他与平常自己设计的双向链表还不太一样。
一个普通的双向链表
对于一个普通的双向链表而言,我们多数会这么设计。
struct person {
int age;
char name[1024];
struct person *prev;
struct person *next;
};
在 struct person 结构中,增加了前一个结构指针和指向后一个数据结构的指针,从而形成了一个循环。不难理解也容易实现,不过这样的双向链表无法提炼出一个框架,也就是说下一次要设计一个 dog 的双向链表又得重新来设计相关的辅助函数,例如数据增加,删除,遍历等等,有没有可能抽象出来一套框架,让他放之四海而皆准呢?答案是可以的,这是 Linux 独有的一些技巧。
Linux 下双链表的基础
Linux 内核下的双向链表的设计为何就会看起来更为高级?其实他只是用到了一个非常常见却独有的特性,它是由 gcc 提供的能力,那就是 container_of 和 offsetof。
什么是 offsetof
offsetof 定义在 linux 内核源码的 include/linux/stddef.h 中。
#ifdef __compiler_offsetof
#define offsetof(TYPE, MEMBER) __compiler_offsetof(TYPE, MEMBER)
#else
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
#endif
可以看到,如果编译器定义了一个内置的 offsetof,那么直接用即可,没有的话,则:
- ((TYPE *)0) 将 0 转型为 TYPE 类型的指针,即 TYPE 类型的数据结构的地址为 0
- ((TYPE *)0)->MEMBER 访问该数据结构的成员
- &((TYPE *)0)->MEMBER 取出该数据成员的地址,此处由于起始地址为 0,那么得到的地址就是这个成员相对于这个 TYPE 数据结构的偏移
- (size_t)(&((TYPE *)0)->MEMBER) 结构转换,对于 32bit 的系统,size_t 就是 unsigned int,对于 64bit 系统,size_t 就是 unsigned long 类型。
offsetof 的实例
#include <stdio.h>
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
struct student
{
char gender;
int id;
int age;
char name[20];
};
void main()
{
int gender_offset, id_offset, age_offset, name_offset;
gender_offset = offsetof(struct student, gender);
id_offset = offsetof(struct student, id);
age_offset = offsetof(struct student, age);
name_offset = offsetof(struct student, name);
printf("gender_offset = %d\n", gender_offset);
printf("id_offset = %d\n", id_offset);
printf("age_offset = %d\n", age_offset);
printf("name_offset = %d\n", name_offset);
}
运行结果如下:
╭─jackieliu@aarch64 ~
╰─➤./a.out
gender_offset = 0
id_offset = 4
age_offset = 8
name_offset = 12
这个地方涉及到一个别的知识点,就是为了 id 的偏移为何是 4 而不是 1,其实如果不是强制让数据结构挨个排列的话,编译器会在这些地方插入一些 payload,目的是为了针对 CPU 的 cacheline 进行优化,在 4 字节对齐的情况下,cacheline 命中是更高的,计算性能有时候会有非常大的一个提升,牺牲一点点内存空间而优化性能,这是完全值得的。当然,要强行挨个对齐也是有办法的,就是在结构体下面标注最小的对齐值为 1 即可。
#include <stdio.h>
#pragma pack(1)
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
struct student
{
char gender;
int id;
int age;
char name[20];
};
void main()
{
int gender_offset, id_offset, age_offset, name_offset;
gender_offset = offsetof(struct student, gender);
id_offset = offsetof(struct student, id);
age_offset = offsetof(struct student, age);
name_offset = offsetof(struct student, name);
printf("gender_offset = %d\n", gender_offset);
printf("id_offset = %d\n", id_offset);
printf("age_offset = %d\n", age_offset);
printf("name_offset = %d\n", name_offset);
}
这样得到的值为:
╭─jackieliu@aarch64 ~
╰─➤ ./a.out
gender_offset = 0
id_offset = 1
age_offset = 5
name_offset = 9
不过这个不重要,和今天要讲的主题完全无关,有兴趣就自行搜索,结构体的对齐也是一个比较有意思的知识点。
什么是 container_of
container_of 定义在 include/linux/kernel.h 中:
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
BUILD_BUG_ON_MSG(!__same_type(*(ptr), ((type *)0)->member) && \
!__same_type(*(ptr), void), \
"pointer type mismatch in container_of()"); \
((type *)(__mptr - offsetof(type, member))); })
他的作用就是用于已知一个成员的地址,然后反推整个结构体的地址,这个其实很好理解,就是用当前成员的地址减去该成员相对于整个结构体的偏移量即可。
Linux 中双向链表的实现
Linux 双向链表介绍
Linux 双向链表的定义主要涉及到两个文件: include/linux/types.h include/linux/list.h
他的设计思想主要是将 struct list_head 嵌入到需要他的结构体中,然后通过 container_of 获取实际 node 的地址。
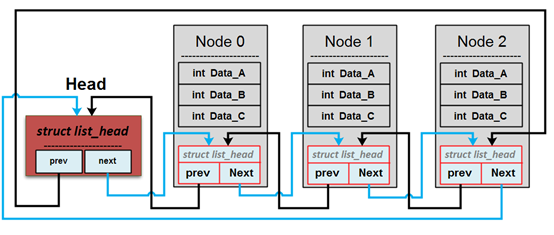
可以看到,从 HEAD 开始往后,不断的增加 Node,通过 Head 我们可以一个个的找到每一个需要的数据,这其中和普通的双链表除了 struct list_head 是嵌入到 Node 中之外,Head 是一个超然的存在,他是无法通过 container_of 找到使用的 Node,因为他并没有嵌入在任何结构中,他的作用就是为了找到链表。
Linux 双向链表的源码解析
节点定义
struct list_head {
struct list_head *prev, *next;
};
初始化节点
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
/**
* INIT_LIST_HEAD - Initialize a list_head structure
* @list: list_head structure to be initialized.
*
* Initializes the list_head to point to itself. If it is a list header,
* the result is an empty list.
*/
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
list->prev = list;
}
LIST_HEAD 和 INIT_LIST_HEAD 都是初始化一个双向链表头,只不过使用的场景不太一样,LIST_HEAD 不但可以初始化,还是重新定义一个双线链表头,而 INIT_LIST_HEAD 是初始化一个之前已经定义了的 list。
添加节点
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
- __list_add(new, prev, next) 的作用是添加节点,将 new 插入到 prev 和 next 之间,在 Linux 内核中 __xxx 的函数都是内部函数,外部调用不到。
- list_add(new, head) 的作用是添加 new 节点,将 new 添加到 head 之后, new 则作为 head 的后继节点。
- list_add_tail(new, head) 的作用是添加 new 节点,即将 new 添加到双向链表的末尾。
删除节点
/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
/*
* Delete a list entry and clear the 'prev' pointer.
*
* This is a special-purpose list clearing method used in the networking code
* for lists allocated as per-cpu, where we don't want to incur the extra
* WRITE_ONCE() overhead of a regular list_del_init(). The code that uses this
* needs to check the node 'prev' pointer instead of calling list_empty().
*/
static inline void __list_del_clearprev(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->prev = NULL;
}
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
/**
* list_del_init - deletes entry from list and reinitialize it.
* @entry: the element to delete from the list.
*/
static inline void list_del_init(struct list_head *entry)
{
__list_del_entry(entry);
INIT_LIST_HEAD(entry);
}
- __list_del(prev, next) 的作用是删除 prev 和 next 之间的所有节点
- __list_del_entry(entry) 的作用是删除 entry 这个节点
- list_del(entry) 也是从双链表中删除 entry 这个节点,并且把 entry 节点悬空,设置其 prev 和 next 为 0xdead000000000000+0x100 和 0xdead000000000000+0x122,这两个值的意思就是,如果在被删除之后再访问这个 entry 那么引起的 panic 会报告问题。
- list_del_init(entry) 除了删除 entry 之外,还会把 entry 作为 HEAD 进行初始化。
替换节点
/**
* list_replace - replace old entry by new one
* @old : the element to be replaced
* @new : the new element to insert
*
* If @old was empty, it will be overwritten.
*/
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
/**
* list_replace_init - replace old entry by new one and initialize the old one
* @old : the element to be replaced
* @new : the new element to insert
*
* If @old was empty, it will be overwritten.
*/
static inline void list_replace_init(struct list_head *old,
struct list_head *new)
{
list_replace(old, new);
INIT_LIST_HEAD(old);
}
- list_replace(old, new) 的作用是用于删除 old 节点,将改位置替换为 new 节点。
- list_replace_init(old, new) 的作用是用于将 old 的位置替换为 new, 并且重新初始化 old 为 HEAD,他的 next 和 prev 都指向自己本身。
判断双链表是否为空
/**
* list_empty - tests whether a list is empty
* @head: the list to test.
*/
static inline int list_empty(const struct list_head *head)
{
return READ_ONCE(head->next) == head;
}
- list_empty 的作用是判断双链表是否为空,他是通过区分表头的 next 节点是否指向表头本身来判断的。
遍历节点
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
/**
* list_for_each_safe - iterate over a list safe against removal of list entry
* @pos: the &struct list_head to use as a loop cursor.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
- list_for_each(pos, n, head) 通常用于获取节点,他不能用于删除节点时使用,因为通过 list_del(pos) 将 pos 的前后指针指向 undefined state,导致 kernel panic,而要是 list_del_init(pos) 将 pos 前后指针指向自身,最终导致死循环。
- list_for_each_safe(pos, n, head) 的话,则可以用于删除节点,因为 pos 的值通过 n 进行了保存,当然,这个函数也可以用于获取节点,只不过没有删除的话,没有必要多一个赋值操作,是为了优化性能。
双链表演示样例
list.h
#ifndef _LIST_HEAD_H
#define _LIST_HEAD_H
// 双向链表节点
struct list_head {
struct list_head *next, *prev;
};
// 初始化节点:设置name节点的前继节点和后继节点都是指向name本身。
#define LIST_HEAD_INIT(name) { &(name), &(name) }
// 定义表头(节点):新建双向链表表头name,并设置name的前继节点和后继节点都是指向name本身。
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
// 初始化节点:将list节点的前继节点和后继节点都是指向list本身。
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
// 添加节点:将new插入到prev和next之间。
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
// 添加new节点:将new添加到head之后,是new称为head的后继节点。
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
// 添加new节点:将new添加到head之前,即将new添加到双链表的末尾。
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
// 从双链表中删除entry节点。
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
// 从双链表中删除entry节点。
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
// 从双链表中删除entry节点。
static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
// 从双链表中删除entry节点,并将entry节点的前继节点和后继节点都指向entry本身。
static inline void list_del_init(struct list_head *entry)
{
__list_del_entry(entry);
INIT_LIST_HEAD(entry);
}
// 用new节点取代old节点
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
// 双链表是否为空
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
// 获取"MEMBER成员"在"结构体TYPE"中的位置偏移
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
// 根据"结构体(type)变量"中的"域成员变量(member)的指针(ptr)"来获取指向整个结构体变量的指针
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
// 遍历双向链表
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
#endif
test.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "list.h"
struct person
{
int age;
char name[20];
struct list_head list;
};
void main(int argc, char* argv[])
{
struct person *pperson;
struct person person_head;
struct list_head *pos, *next;
int i;
// 初始化双链表的表头
INIT_LIST_HEAD(&person_head.list);
// 添加节点
for (i=0; i<5; i++)
{
pperson = (struct person*)malloc(sizeof(struct person));
pperson->age = (i+1)*10;
sprintf(pperson->name, "%d", i+1);
// 将节点链接到链表的末尾
// 如果想把节点链接到链表的表头后面,则使用 list_add
list_add_tail(&(pperson->list), &(person_head.list));
}
// 遍历链表
printf("==== 1st iterator d-link ====\n");
list_for_each(pos, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
printf("name:%-2s, age:%d\n", pperson->name, pperson->age);
}
// 删除节点age为20的节点
printf("==== delete node(age:20) ====\n");
list_for_each_safe(pos, next, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
if(pperson->age == 20)
{
list_del_init(pos);
free(pperson);
}
}
// 再次遍历链表
printf("==== 2nd iterator d-link ====\n");
list_for_each(pos, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
printf("name:%-2s, age:%d\n", pperson->name, pperson->age);
}
// 释放资源
list_for_each_safe(pos, next, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
list_del_init(pos);
free(pperson);
}
}
更多奇怪的双链表函数
以上的函数,几乎就是平常普通开发者用到最多的接口,他们大多数都非常容易理解且使用方便,如果理解到此处觉得已经可以了的话,也足够在内核中理解双链表的使用,不过,内核还提供了许多其他的奇怪的,难以理解的函数接口,针对与这些函数,我还是打算进一步深入的分析理解,并有演示使用场景,因为我自己初次碰到时,也搞不清楚他们的含义以及使用场景。