Linux 通用块层 bio 详解
Contents
Linux Block 层在 Linux 内核设计之初就作为几大子系统存在,当然这也是得益于他的前辈 Unix 等优秀的设计。作为 IO 子系统的中间层,他为上层输出接口,为下层提供数据,像个勤劳的小蜜蜂,本文介绍通用块层中的最具传奇色彩的 bio,他就像是一个原子,是在整个 block 层的最小单位,不可分割。
bio 的组成
作为最小单位以及传输介质,那么具体应该长得如何?他又承载着那些信息?
struct bio {
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev;
unsigned int bi_flags; /* status, command, etc */
int bi_error;
unsigned long bi_rw; /* 末尾 bit 表示 READ/WRITE,
* 起始 bit 表示优先级
*/
struct bvec_iter bi_iter;
/* 当完成物理地址合并之后剩余的段的数量 */
unsigned int bi_phys_segments;
/*
* To keep track of the max segment size, we account for the
* sizes of the first and last mergeable segments in this bio.
*/
unsigned int bi_seg_front_size;
unsigned int bi_seg_back_size;
/* 关联 bio 的数量 */
atomic_t __bi_remaining;
bio_end_io_t *bi_end_io;
void *bi_private;
unsigned short bi_vcnt; /* how many bio_vec's */
/*
* Everything starting with bi_max_vecs will be preserved by bio_reset()
*/
unsigned short bi_max_vecs; /* max bvl_vecs we can hold */
/* 当前 bio 的引用计数,当该数据为 0 时才可以 free */
atomic_t __bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
struct bio_set *bi_pool;
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
* 表示跟在 bio 后面的数据集合
*/
struct bio_vec bi_inline_vecs[0];
};
bio 结构体包含了大量的基础信息,这些都是一个基本单元的属性,他们代表着当前这个 bio 的状态,比如是读还是写或者是一些特殊的操作命令等,在 bio 的尾部携带了一个 bi_inline_vecs 数组1,这就是一个 bio 数据所在部分,相当于这个结构体描述的都只是元数据部分,实际数据都包含在紧跟其后的 bio_vec 中,那么这个 bio_vec 何许人也?
最小数据单位 bio_vec
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
顾名思义,bio_vec 就是一个 bio 的数据容器,专门用来保存 bio 的数据,当然他是这个 bio 大集体的一个最小项,刚刚说了 bio 是通用块层的最小集,而这个 bio_vec 则是组成 bio 数据的最小单位,他包含了一块数据所在的页,这块数据所在的页内偏移以及长度,通过这些信息就可以很清晰的描述数据具体位于什么位置,通过对这些数据的整合,可以将他们添加到 SGL(散列表) 中直接发送给后端硬件设备。
迭代器 bvec_iter
寻遍整个 bio 发现居然没有携带需要下盘的扇区编号以及当前 bio 的大小,这个很尴尬,但确实如此,相当于 bio 作为一辆汽车,他携带了货物但是没告诉他目的地这不是完蛋了吗?不是,真正的目的地保存在这个 bvec_iter 中,作为一个迭代器,自然他的使命就是用来遍历 bvec,也就是 bio 数据区。那么他好比就是这辆 bio 汽车的货物分拣员,自然我的目的地不必贴到车上,直接告诉分拣员也是可以的,因为后面的事情可不是这辆汽车再做,而是分拣员需要逐个卸货的时候用。一起来看看迭代器长什么样?
struct bvec_iter {
sector_t bi_sector; /* device address in 512 byte sectors */
unsigned int bi_size; /* residual I/O count */
unsigned int bi_idx; /* current index into bvl_vec */
unsigned int bi_bvec_done; /* number of bytes completed in current bvec */
};
bio 的逻辑架构图
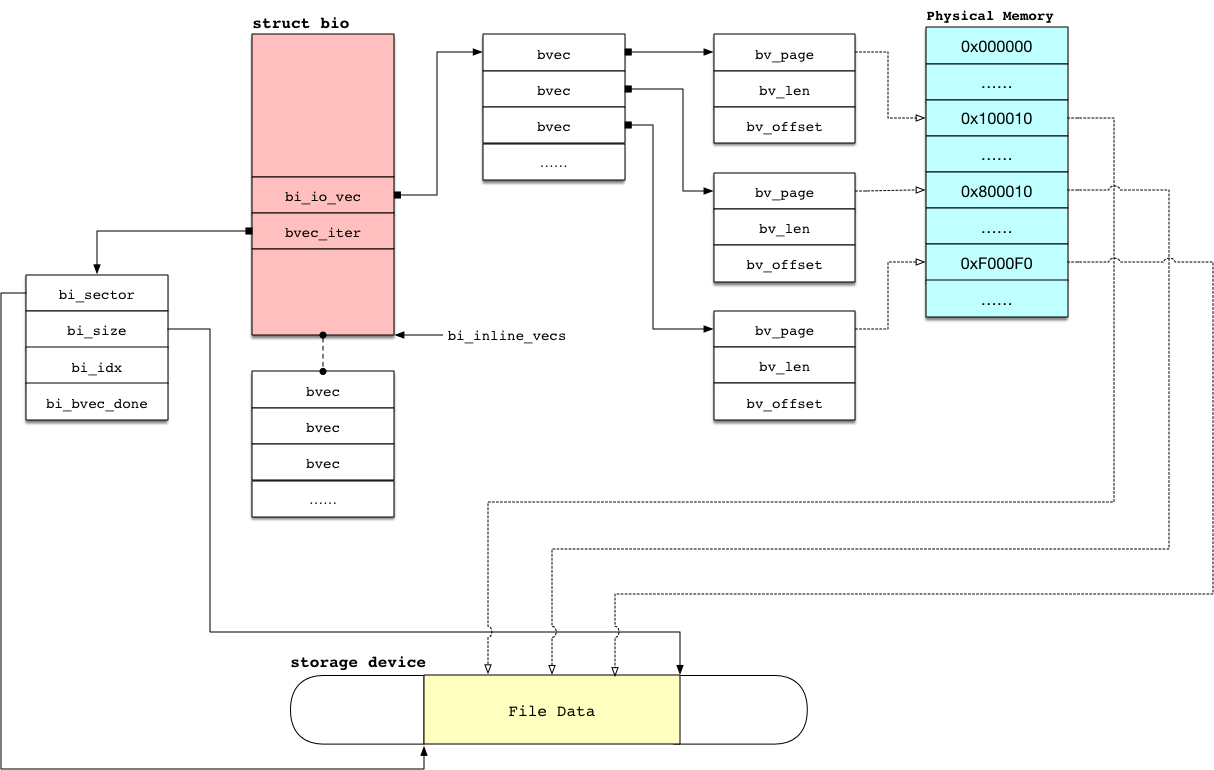
关于 bi_io_vec 和 bi_inline_vecs 的关系
细心的朋友会发现,一个 bio 会有两个字段用来描述 bio 携带的数据,对于没有深入了解的人来讲会比较困惑,其实也比较容易理解,bio 结构在申请内存的时候会多申请 4 个 bvec 的位置跟随 bio 结构体上,这就是 bi_inline_vecs ,他是用来存放内联数据(不能太多,因为申请了不用就会造成内存浪费),当往该 bio 注入数据时,小块的 bio 会直接使用这个内联的数据区域保存小于 4 个 bvec 的信息,而无需重新调用 kmalloc 申请内存,减少了一次内存申请操作,牺牲一小部分内存达到对小 bio 的加速(内存申请过程很长且相对较慢),然后为了兼容后端的其他接口,会直接将 bi_io_vec 指针直接指向 bi_inline_vecs 所在的位置,目的就是告诉后端,数据存放在 bi_inline_vecs 位置上。如果超过 4 个以上的 bvec 才足够完整描述本次 IO 的全部数据,那么 bi_inline_vecs 字段是被直接忽略的,尽管他内存很早就申请好了,但是并不会被采用,而是需要重新自内存管理单元重新申请足额的内存保存这一次的 IO 数据,这就是前面说的一点点的内存浪费的原因。
- 这是一个 0 长度数组,这不是一个标准 C 的做法,用 std=c99 肯定是编译不过去的,这是一个 std=gnu99 扩展标准的一个特定用法,主要是在结构体中插入一个可以标识紧跟之后的内存的方法,这种方式在 Linux 内核中很常见,是个很巧妙的办法。 ↩︎